








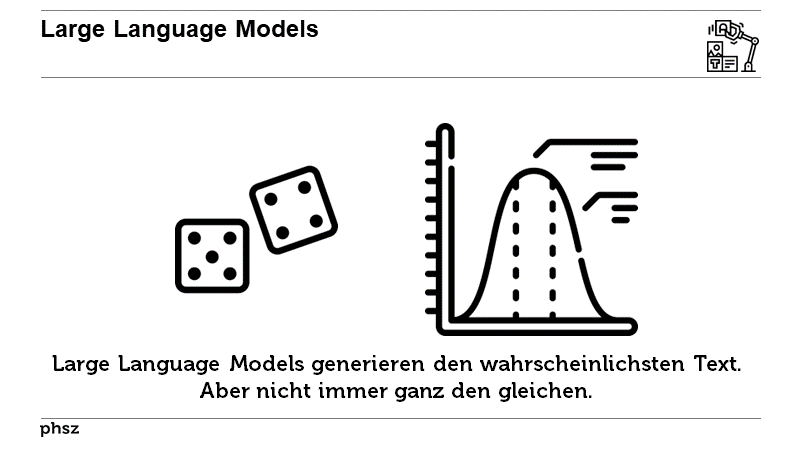
Generative Machine-Learning-Systeme (GMLS) computer-generated text |
|
 BiblioMap
BiblioMap 
 Synonyme
Synonyme
computergeneriertes Schreiben, Schreiben durch Computer, computergenerierte Texte, Schreibroboter, Textbots, computational journalism, machine written news, automated journalism, natural language generation, GMLS, large language model, LLM, Generative Machine-Learning-Systeme
 Definitionen
Definitionen
 In DigComp
3.0, generative AI is defined as a subset of AI that
uses specialised machine learning models designed
to produce a wide and general variety of outputs,
capable of a range of tasks and applications, such
as generating text, image or audio (Abendroth-Dias
et al., 2025).
In DigComp
3.0, generative AI is defined as a subset of AI that
uses specialised machine learning models designed
to produce a wide and general variety of outputs,
capable of a range of tasks and applications, such
as generating text, image or audio (Abendroth-Dias
et al., 2025). KI-gestütztes Schreiben beschreibt einen Schreibprozess, der durch eine KI-basierte Software in unterschiedlichen Phasen des Schreibprozesses und mit unterschiedlicher Intensität und Funktionalität unterstützt wird. Er gliedert sich in die beiden Teilbereiche KI-gestützte Textbearbeitung und KI-gestützte Textgenerierung. Die primären Zielsetzungen des KI-gestützten Schreibens sind die effizientere Bearbeitung vorhandener Texte oder das automatisierte Generieren neuer Textsequenzen.
KI-gestütztes Schreiben beschreibt einen Schreibprozess, der durch eine KI-basierte Software in unterschiedlichen Phasen des Schreibprozesses und mit unterschiedlicher Intensität und Funktionalität unterstützt wird. Er gliedert sich in die beiden Teilbereiche KI-gestützte Textbearbeitung und KI-gestützte Textgenerierung. Die primären Zielsetzungen des KI-gestützten Schreibens sind die effizientere Bearbeitung vorhandener Texte oder das automatisierte Generieren neuer Textsequenzen. Eine andere Ausprägung des Narrative-Science-Systems, bei dem die Firma auch schon Konkurrenten hat, ist die Generierung der verpflichtenden Quartalsberichte für börsennotierte Unternehmen. Diese Berichte werden meist ohnehin nur von ein paar Dutzend Investmentanalysten gelesen und ausgewertet – und von Börsen-Handelsalgorithmen. Das Prinzip der Berichtgenerierung bleibt gleich: Aktuelle Geschäftszahlen, die aus der Unternehmenssoftware extrahiert worden sind, werden mit denen aus den vergangenen Quartalen, Zahlenwerken über die Situation in den verschiedenen Absatzmärkten und weiteren relevanten Daten zum Faktengrundgerüst für den Bericht zusammengestellt.
Eine andere Ausprägung des Narrative-Science-Systems, bei dem die Firma auch schon Konkurrenten hat, ist die Generierung der verpflichtenden Quartalsberichte für börsennotierte Unternehmen. Diese Berichte werden meist ohnehin nur von ein paar Dutzend Investmentanalysten gelesen und ausgewertet – und von Börsen-Handelsalgorithmen. Das Prinzip der Berichtgenerierung bleibt gleich: Aktuelle Geschäftszahlen, die aus der Unternehmenssoftware extrahiert worden sind, werden mit denen aus den vergangenen Quartalen, Zahlenwerken über die Situation in den verschiedenen Absatzmärkten und weiteren relevanten Daten zum Faktengrundgerüst für den Bericht zusammengestellt.
Die Berichtgenerierungssoftware erzeugt dann daraus nach den gleichen Methoden wie bei der automatischen Sportberichterstattung einen Fließtext, wenn gewünscht mit Tabellen, der sich nicht ohne weiteres von solchen unterscheiden läßt, die von Menschen geschrieben wurden. Bei Quartalsberichten sind die teilweise gesetzlich vorgeschriebenen Inhalte und die daraus abgeleitete Struktur ohnehin noch mal ähnlicher und wiederkehrender als bei Sportberichten. Niemand erwartet hier literarische Höchstleistungen. Im Gegenteil: Die Algorithmen auf der anderen Seite, die zur Auswertung solcher Quartalsberichte geschrieben wurden, funktionieren besser, wenn weitgehend auf sprachliche Dekorationen verzichtet wird.
Auch menschliche Kreativität, die bisher als nicht oder nur begrenzt durch Algorithmen ersetzbar galt, ist in einigen Bereichen weitaus weniger unersetzbar als angenommen. Ein drastisches Beispiel hierfür liefert die Firma Narrative Sciences, die es sich zum Ziel gesetzt hat, ihre Software Geschichten erzählen zu lassen. Wie es sich für ein gewinnorientiertes Start-up gehört, geht es dabei nicht um Märchen oder Sagen, sondern um Quartalsberichte von Unternehmen und – durchaus beeindruckend – um Sportberichterstattung.
Durch Analyse von Millionen von Zeitungsartikeln über in den USA beliebte Sportarten wie Baseball oder Basketball, die mit den über jedes Spiel erfaßten Daten über Spielaktionen, Ballbesitz, Tore, statistische Auffälligkeiten und Rekorde und so weiter verglichen wurden, lernten die Systeme von Narrative Science, wie Menschen über ein Spiel schreiben. Typische Phrasen und Wortverbindungen der Sportberichterstattung für die jeweiligen Situationen wurden extrahiert und in einer Datenbank gespeichert. Ergibt sich aus den Daten des Spiels, über das die Software gerade einen Bericht schreibt, eine ähnliche Situation, werden die dazugehörigen Satzbestandteile zur Beschreibung herausgesucht.
Aus dem Kontext der Daten und daraus, wann in der von der Software belieferten Zeitung diese Satzbausteine zuletzt verwendet wurden – man will schließlich keine zu auffälligen Wiederholungen von Formulierungen –, und weiteren Modulen, die unter anderem auf korrekten Satzbau und Grammatik achten, ergeben sich letztendlich die fertigen Sätze und Absätze eines Artikels. Die nackten, formalisierten Daten werden zu einer Geschichte, wie sie ein Mensch erzählen würde.
 Bemerkungen
Bemerkungen
 Etwas polemisch könnte man festhalten, dass Algorithmen nur Schreibaufgaben unterminieren, die an sich schon problematisch sind.
Etwas polemisch könnte man festhalten, dass Algorithmen nur Schreibaufgaben unterminieren, die an sich schon problematisch sind. Plagiarism software will not detect essays written by Transformers, because the text is generated, not copied. A Google search of the essay shows that each sentence is original.
Plagiarism software will not detect essays written by Transformers, because the text is generated, not copied. A Google search of the essay shows that each sentence is original. Algorithmen schreiben schneller
und billiger als Menschen. Ihr
Hauptvorteil ist jedoch: Sie können
ihre Texte dynamisch an die Leser
anpassen. Den Online-Handel wird
das schneller verändern als den
Journalismus.
Algorithmen schreiben schneller
und billiger als Menschen. Ihr
Hauptvorteil ist jedoch: Sie können
ihre Texte dynamisch an die Leser
anpassen. Den Online-Handel wird
das schneller verändern als den
Journalismus.") Es ist wichtig, zwischen intelligenten Tutorensystemen (ITS) und generativer KI wie
ChatGPT zu unterscheiden. Generative KI ist nicht oder kaum als Tutor für solche
Lernende geeignet, die nur über grundlegende Kenntnisse eines Lerngegenstandes
verfügen!
Es ist wichtig, zwischen intelligenten Tutorensystemen (ITS) und generativer KI wie
ChatGPT zu unterscheiden. Generative KI ist nicht oder kaum als Tutor für solche
Lernende geeignet, die nur über grundlegende Kenntnisse eines Lerngegenstandes
verfügen!
Wer sich z. B. Anfang 2023 ein KI-Urteil anhand von ChatGPT gebildet und sich seither nicht mehr mit der Technologie auseinandergesetzt hat, wird dieser nicht nur unrecht tun, sondern den aktuellen Entwicklungsstand, geschweige denn auch mögliche Zukünfte, gänzlich falsch bewerten.
 Da Englisch gewissermaßen
die Leitsprache von Systemen
wie GPT-4 darzustellen scheint,
d.h. eine klare Tendenz besteht, englische
Stilprinzipien auf andere Sprachen
zu übertragen, droht die Proliferation
artifizieller Texte die Hegemonie des
Englischen und des mit ihm verbundenen
Schreib- und Denkstils weiter zu
stärken.
Da Englisch gewissermaßen
die Leitsprache von Systemen
wie GPT-4 darzustellen scheint,
d.h. eine klare Tendenz besteht, englische
Stilprinzipien auf andere Sprachen
zu übertragen, droht die Proliferation
artifizieller Texte die Hegemonie des
Englischen und des mit ihm verbundenen
Schreib- und Denkstils weiter zu
stärken. Large language models are our second contact with A.I. We cannot afford to lose again. But on what basis should webelieve humanity is capable of aligning these new forms of A.I. to our benefit? If we continue with business as usual,the new A.I. capacities will again be used to gain profit and power, even if it inadvertently destroys the foundations ofour society.
Large language models are our second contact with A.I. We cannot afford to lose again. But on what basis should webelieve humanity is capable of aligning these new forms of A.I. to our benefit? If we continue with business as usual,the new A.I. capacities will again be used to gain profit and power, even if it inadvertently destroys the foundations ofour society. So wie kein Autor unter seinen Text
schreibt: „Dieser Artikel wurde mit Word
16.66.1 geschrieben und mit dessen
Rechtschreibkorrektur überprüft“, ergibt
es in Zukunft keinen Sinn, alle KI-Tools
aufzulisten, die bei der Recherche und
Formulierung geholfen haben. Wichtiger
ist es, dass immer ein Autor für den Inhalt
eines Textes geradesteht und verantwortlich
gemacht werden kann.You should be worried. GPT-3 and programs like it are starting to take over
routine writing tasks like composing blogs and writing news stories. They
are good at summarizing magazine articles and academic papers. They can
write convincing poetry. The computer games industry is adopting these
programs to offer lifelike characters, with personalities and emotions, who
can engage in deep conversation with players.
So wie kein Autor unter seinen Text
schreibt: „Dieser Artikel wurde mit Word
16.66.1 geschrieben und mit dessen
Rechtschreibkorrektur überprüft“, ergibt
es in Zukunft keinen Sinn, alle KI-Tools
aufzulisten, die bei der Recherche und
Formulierung geholfen haben. Wichtiger
ist es, dass immer ein Autor für den Inhalt
eines Textes geradesteht und verantwortlich
gemacht werden kann.You should be worried. GPT-3 and programs like it are starting to take over
routine writing tasks like composing blogs and writing news stories. They
are good at summarizing magazine articles and academic papers. They can
write convincing poetry. The computer games industry is adopting these
programs to offer lifelike characters, with personalities and emotions, who
can engage in deep conversation with players.
In der Schweiz setzen die grossen Medienhäuser in diesen Bereichen seit einigen Jahren ebenfalls automatisierte Textproduktion ein (Beck, 2023). Tamedia erstellt seit 2018 Berichte zu Abstimmungen auf Gemeindeebene automatisiert mit dem Textroboter Tobi (Fürst & Grubenmann, 2019). Lena, der Textroboter von Keystone-SDA, produziert automatisiert mehrsprachige Kurztexte zu den Resultaten nationaler und kantonaler Abstimmungen (Fürst & Grubenmann, 2019). Auch CH Media nutzt KI, um Texte zu News aus Gemeinden oder Resultaten im Regionalsport zu generieren (Aargauer Zeitung, 2021).
Die Arbeitsweise der Algorithmen, ihre Heranziehung von großen Mengen archivierter Artikel, um damit das Skelett der Daten mit Formulierungen zu umkleiden, die sie für den Menschen besser les- und verstehbar machen, eignet sich jedoch bei weitem nicht für alle Arten von Text. Sie wird gut funktionieren, wenn die zu beschreibenden Sachverhalte anhand von strukturierten Daten vorliegen, die »nur noch« in Prosa umgesetzt werden müssen. Andere Algorithmen sind jedoch zumindest in begrenztem Maße in der Lage, auch aus sogenanntem unstrukturiertem Text, also Nachrichtentickermeldungen oder Dokumenten, wohlfeile strukturierte Informationen zu extrahieren, die dann wiederum von anderen Algorithmen weitergenutzt werden können. Das dritte Beispiel des computational journalism dürfte am deutlichsten machen, dass Computer anfangen, kognitive
Leistungen für Menschen zu übernehmen. Mehrere Firmen
verkaufen bereits erfolgreich computergenerierte Sport- und
Börsenberichte an Zeitungen. Je mehr Daten zu einem Ereignis
digital verfügbar sind, desto einfacher ist es für einen Computer,
daraus einen Artikel zu formulieren, der von Menschen nicht als
vom Computer geschrieben erkannt wird. In den USA eignet sich
zum Beispiel Baseball sehr, da in einem solchen Spiel viele Daten
anfallen, aus denen sich der Spielverlauf ablesen lässt. Im Finanzbereich
wird das Verfassen von Jahresberichten börsennotierter
Unternehmen immer heikler, da falsche Formulierungen juristische
Konsequenzen haben könnten. Also wird auch diese Arbeit
Computern übertragen, die aus den Geschäftsdaten einen trockenen
Prosatext generieren. Computer schreiben erfolgreich Texte –
damit verschiebt sich unaufhaltsam die Grenze dessen, was wir
für automatisierbar halten.
Das dritte Beispiel des computational journalism dürfte am deutlichsten machen, dass Computer anfangen, kognitive
Leistungen für Menschen zu übernehmen. Mehrere Firmen
verkaufen bereits erfolgreich computergenerierte Sport- und
Börsenberichte an Zeitungen. Je mehr Daten zu einem Ereignis
digital verfügbar sind, desto einfacher ist es für einen Computer,
daraus einen Artikel zu formulieren, der von Menschen nicht als
vom Computer geschrieben erkannt wird. In den USA eignet sich
zum Beispiel Baseball sehr, da in einem solchen Spiel viele Daten
anfallen, aus denen sich der Spielverlauf ablesen lässt. Im Finanzbereich
wird das Verfassen von Jahresberichten börsennotierter
Unternehmen immer heikler, da falsche Formulierungen juristische
Konsequenzen haben könnten. Also wird auch diese Arbeit
Computern übertragen, die aus den Geschäftsdaten einen trockenen
Prosatext generieren. Computer schreiben erfolgreich Texte –
damit verschiebt sich unaufhaltsam die Grenze dessen, was wir
für automatisierbar halten. Bereits 2010 wurde die Anwendung Stats Monkey vorgestellt, die kurze Berichte zu Baseballspielen anfertigen kann. Alles, was das Programm dafür benötigt, sind umfassende Daten zu den Spielen, die mittlerweise routinemäßig erhoben und dank verbesserter algorithmischer Bilderkennung und neuer Sensoren immer detaillierter werden. Das Programm extrahiert aus den Daten die entscheidenden Momente und Akteure eines Spiels, erkennt charakteristische Muster im Spielverlauf (etwa “frühe Führung stetig ausgebaut”, “dramatische Aufholjagd” oder Ähnliches) und generiert darauf aufbauend eigene Berichte. Dabei kann eine Vielzahl von Variablen bestimmt werden, etwa ob ein Artikel aus der Perspektive eines neutralen Beobachters oder vom Standpunkt eines der beiden Teams geschrieben werden soll. Oder man kann, weil Eltern nicht gerne über die Fehler ihrer Kinder lesen, festlegen, dass vor allem die gelungenen Spielzüge hervorgehoben werden sollen, wenn es um Partien in der Schülerliga geht. Der Algorithmus wurde rasch patentiert, und aus dem ursprünglich interdisziplinären Forschungsprojekt wurde ein Start-up-Unternehmen: Narrative Science. Dieses bietet heute Texte aller Art an, neben Sport- vor allem auch Finanzberichterstattung, ebenfalls ein Feld, für das statistische Informationen in Fülle vorliegen. Diese Texte werden in renommierten Medien wie dem Wirtschaftsmagazin Forbes veröffentlicht und dort mit dem Autorenvermerk “narrative science” gekennzeichnet. Noch beschränken sich diese Beiträge auf relativ einfache Themen. Dabei soll es aber nicht bleiben. Auf die Frage, wie groß der Anteil algorithmisch verfasster Nachrichten in fünfzehn Jahren sein werde, antwortete Kristian Hammond, Technologiechef von Narrative Science und einer der Gründer des Unternehmens, 2012 selbstbewusst mit “neunzig Prozent” – und fügte gleich noch hinzu, dass ein Algorithmus schon in fünf Jahren zum ersten Mal den Pulitzer-Preis gewinnen werde.[195] Da wird einiges an Hype und Selbstmarketing mitschwingen, aber als generelle Einschätzung ist seine Aussage nicht unglaubwürdig.
Bereits 2010 wurde die Anwendung Stats Monkey vorgestellt, die kurze Berichte zu Baseballspielen anfertigen kann. Alles, was das Programm dafür benötigt, sind umfassende Daten zu den Spielen, die mittlerweise routinemäßig erhoben und dank verbesserter algorithmischer Bilderkennung und neuer Sensoren immer detaillierter werden. Das Programm extrahiert aus den Daten die entscheidenden Momente und Akteure eines Spiels, erkennt charakteristische Muster im Spielverlauf (etwa “frühe Führung stetig ausgebaut”, “dramatische Aufholjagd” oder Ähnliches) und generiert darauf aufbauend eigene Berichte. Dabei kann eine Vielzahl von Variablen bestimmt werden, etwa ob ein Artikel aus der Perspektive eines neutralen Beobachters oder vom Standpunkt eines der beiden Teams geschrieben werden soll. Oder man kann, weil Eltern nicht gerne über die Fehler ihrer Kinder lesen, festlegen, dass vor allem die gelungenen Spielzüge hervorgehoben werden sollen, wenn es um Partien in der Schülerliga geht. Der Algorithmus wurde rasch patentiert, und aus dem ursprünglich interdisziplinären Forschungsprojekt wurde ein Start-up-Unternehmen: Narrative Science. Dieses bietet heute Texte aller Art an, neben Sport- vor allem auch Finanzberichterstattung, ebenfalls ein Feld, für das statistische Informationen in Fülle vorliegen. Diese Texte werden in renommierten Medien wie dem Wirtschaftsmagazin Forbes veröffentlicht und dort mit dem Autorenvermerk “narrative science” gekennzeichnet. Noch beschränken sich diese Beiträge auf relativ einfache Themen. Dabei soll es aber nicht bleiben. Auf die Frage, wie groß der Anteil algorithmisch verfasster Nachrichten in fünfzehn Jahren sein werde, antwortete Kristian Hammond, Technologiechef von Narrative Science und einer der Gründer des Unternehmens, 2012 selbstbewusst mit “neunzig Prozent” – und fügte gleich noch hinzu, dass ein Algorithmus schon in fünf Jahren zum ersten Mal den Pulitzer-Preis gewinnen werde.[195] Da wird einiges an Hype und Selbstmarketing mitschwingen, aber als generelle Einschätzung ist seine Aussage nicht unglaubwürdig.Verwandte Objeke
 Chat-GPT
Chat-GPT Künstliche Intelligenz (KI / AI)
Künstliche Intelligenz (KI / AI) Generative Pretrained Transformer 3 (GPT-3)
Generative Pretrained Transformer 3 (GPT-3) Generative Pretrained Transformer 4 (GPT-4)
Generative Pretrained Transformer 4 (GPT-4) Textgeneratoren-Verbot
Textgeneratoren-Verbot CoautorInnenlandkarte
CoautorInnenlandkarte
 Relevante Personen
Relevante Personen
Häufig erwähnende Personen
DorisWeßels
 Jo
JoBager
BeatDöbeli Honegger
IsabellaBuck
PhilippeWampfler
AndreaTrinkwalder
FabianLang
HartmutGieselmann
 Katharina A.
Katharina A.Zweig
RuthFulterer
BeatrixBusse
IngoKleiber
MarcelSalathé
JoachimLaukenmann
Emily M.Bender
RenéPeinl
FlorianNuxoll
UweEbbinghaus
EthanMollick
EvaWolfangel
KlausZierer
PinaMerkert
EdithHollenstein
HendrikHaverkamp
HannesBajohr
Häufig co-zitierte Personen
Emily M.Bender
AngelinaMcMillan-Major
ShmargaretShmitchell
TimnitGebru
IlyaSutskever
DarioAmodei
GirishSastry
EricSigler
MarkChen
ChristopherHesse
ClemensWinter
JeffreyWu
Daniel M.Ziegler
AdityaRamesh
TomHenighan
ArielHerbert-Voss
MateuszLitwin
AmandaAskell
RewonChild
PranavShyam
ArvindNeelakantan
JaredKaplan
MelanieSubbiah
NickRyder
BenjaminMann
KewalDhariwal
SandhiniAgarwal
BenjaminChess
JackClark
ChristopherBerner
SamMcCandlish
AlecRadford
Tom B.Brown
PrafullaDhariwal
GretchenKrueger
ScottGray
Statistisches Begriffsnetz
 14 Vorträge von Beat mit Bezug
14 Vorträge von Beat mit Bezug


- Schule - Medien - Informatik - Worauf sollen wir uns einstellen?
Eröffnungsreferat an der Kick-Off-Veranstaltung zur dynamischen ICT-Strategie des Kantons Thurgau
PH Thurgau, Kreuzlingen, 24.06.2015
- 1001 Fragen zu Digitalisierung und Fachdidaktik
Hauptvortrag von Ralf Romeike und Beat Döbeli Honegger an der Jahrestagung der Gesellschaft für Fachdidaktik (GFD)
Regensburg, bzw. Internet, 23.09.2020

- Anforderungen an die Lehrkräftebildung MIT - ÜBER - IN digitalen Medien
QLB-BMBF-Kongress Berlin, 22.11.2021

- Die Reise nach Digitalien
PH VS / HEP VS, Sion, 18.01.2023
- ChatGPT - der iPhone-Moment für KI?
Klausur PHSZ, Oberägeri, 14.02.2023
- ChatGPT - der iPhone-Moment des maschinellen Lernens
AG Fremdsprachen Kammer PH swissuniversities, 25.05.2023
- ChatGPT - der iPhone-Moment des maschinellen Lernens
NMS Bern, 07.06.2023

- ChatGPT - Refresher
Dozierenden-Klausur PHSZ, Goldau, 26.06.2023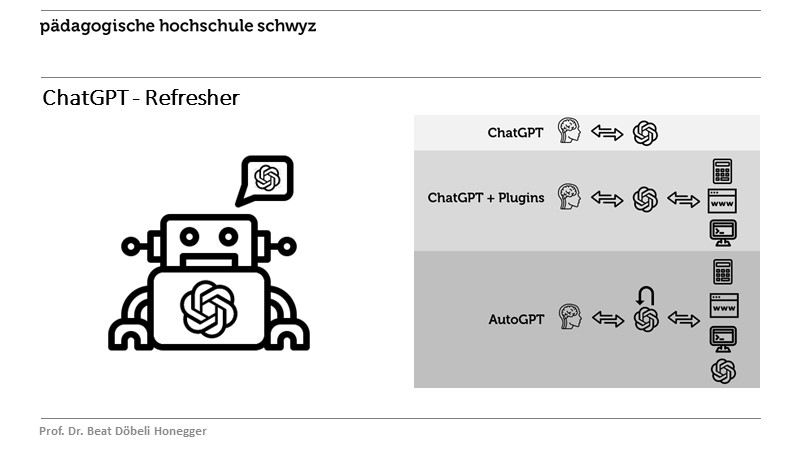

- BBZGPT
Berufsbildungszentrum Goldau, 17.08.2023
- Nachrichtenkompetenz – und jetzt auch noch ChatGPT & Co.
Tagung "Nachrichtenkompetenz auf Sekundarstufe II" von ZHAW und SRG public value, 03.11.2023
- ChatGPT & Co. – eine Etappe auf der Reise nach Digitalien
CAS Lernreise, 19.01.2024

- Grundlagenpapier Lernplattformen
Kurzpräsentation an der Sitzung der Regionalkonferenzen
Haus der Kantone, Bern, 26.03.2026

- Wenn der Computer das Fahrrad für den Geist ist...
Eröffnungskeynote am AI-Festival Ostschweiz
SQUARE, HSG, St. Gallen, 04.06.2026

11 Einträge in Beats Blog
- Dem Computer sagen, was er 3D-drucken soll (Mai 2026)
- Biblionetz - Wiki - GMLS - und was ist meine Aufgabe? (April 2026)
- Experimente mit lokalen GMLS (April 2026)
- Machmaschinen als Dilemma und IT-Sicherheits-Horror (Januar 2026)
- Future Shock Level 2026 (Januar 2026)
- The Sirens' Call (Dezember 2025)
- GMLS in der Hand von Lernenden (September 2025)
- Boah, aus X lässt sich jetzt Y generieren! (September 2024)
- Evaluationsstruktur 'Lernen mit GMLS' (September 2024)
- Warum GMLS und nicht einfach LLM? (Juli 2024)
- Verlängert die Digitalisierung die notwendige Ausbildungszeit? (Juni 2023)
Erwähnungen auf anderen Websites im Umfeld von Beat Döbeli Honegger
| Website | Webseite | Datum |
|---|---|---|
| ChatGPT & Co. und die Schule | Literatur | 05.04.2023 |
 Zitationsgraph (Beta-Test mit vis.js)
Zitationsgraph (Beta-Test mit vis.js)
 902 Erwähnungen
902 Erwähnungen
- Umgang mit generativen KI-Modellen - Ein Handlungsleitfaden (Thüringer Ministerium für Bildung. Jugend und Sport)

- AI risk must be treated as seriously as climate crisis, says Google DeepMind chief (Dan Milmo)
- How generative AI expands curiosity and understanding with LearnLM (Ben Gomes)
- Quantifying ChatGPT’s gender bias (Sayash Kapoor, Arvind Narayanan)
- Rote Karte: Bliki, der neuste Autor des «Blick» (Thomas Schwendener)
- An AI Learning Hierarchy (Peter J. Denning, Ted G. Lewis)
- KI im Studium aus Studierendensicht - Nutzung, Fähigkeiten und Einstellungen Studierender zu KI (Ulf-Daniel Ehlers, Emily Rauch)
- Power Hungry Processing - Watts Driving the Cost of AI Deployment? (Sasha Luccioni, Yacine Jernite, Emma Strubell)
- How People Use ChatGPT (Aaron Chatterji, Thomas Cunningham, David J. Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, Kevin Wadman)
- Wissenschaftliches Schreiben mit KI - Schreibmaschine oder Programmierung? (Noah Bubenhofer)
- Cut the bullshit - why GenAI systems are neither collaborators nor tutors (Gene Flenady, Robert Sparrow)
- Generative artificial intelligence in secondary STEM education in the light of Human Flourishing - a scoping literature review (Alissa Fock, Hans-Stefan Siller)
- Navigating AI in Education - Pupils’ perspectives on the role of AI in the classroom (Oxford University Press)

- Artificial Intelligence Index Report 2024 (Stanford Institute for Human-Centered Artificial Intelligence)
- Schreibende KI - ein interdisziplinärer Diskurs - Perspektiven über den Sinn oder Unsinn von schreibender KI (Alke Martens, Clemens H. Cap)
- Textgenerierende KI: Ein kritisches Essay (Clemens H. Cap)
- Hilfe, meine KI kann schreiben! (Alke Martens)
- Wie hätte Joseph Weizenbaum die aktuellen Entwicklungen kommentiert? (Alke Martens, Yvonne Düwel, Fabian Dellwing)
- Die Mensch-KI-Ausrichtung (Robin Nicolay)
- Large Language Models: Technische Grundlagen (Sebastian Bader, Thomas Kirste)
- Einsatz KI-gestützter Systeme für Literaturreviews - Explorative Analyse und kritische Reflexion (Michael Fellmann, Henrik Bongertmann, Niklas Götz, Carl Pommerencke)
- Deutschunterricht mit ChatGPT & Co - wohin die Reise gehen könnte (Kristina Koebe, Anne Elli Settgast, Jens Liebich, Tilman von Brand)
- Textgenerierende KI im Verwaltungsverfahren - Politische Ziele, Regulierung und Verwaltungspraxis im Spannungsfeld (Sebastian Schröder)
- Textgenerierende KI und das Strafrecht - Herausforderungen beim Einsatz von textgenerierender KI in der Strafrechtwissenschaft und -lehre (Juliane Schwarz-Ladach)
- Schreibende KI im anwaltlichen Bereich - Ein Test in der verkehrsrechtlichen Praxis (Silke Minnerup)
- Ethik von ChatGPT in der Medizin (Johann-Christian Põder, Bernd F. M. Romeike)
- Textgenerierende KI: Ein kritisches Essay (Clemens H. Cap)
- Handbook of Artificial Intelligence in Higher Education (Stefan Popenici, Jürgen Rudolph, Fadhil Ismail, Shannon Tan)
- Erste Flugstunden - CoPilot: Microsoft Office mit KI (Spezialthema in c't 8/2024) (424)
- Chat-GPT gefährdet die gymnasiale Bildung (Robin Schwarzenbach) (1899)
- Leitfaden: Verwendung generativer KI-Systeme bei Maturitäts- und Projektarbeiten an Zürcher Mittelschulen (Digital Learning Hub Sek II (DLH)) (2000)
- Arbeitsfrei - Eine Entdeckungsreise zu den Maschinen, die uns ersetzen (Constanze Kurz, Frank Rieger) (2013)
- Journalist versus news consumer - The perceived credibility of machine written news (Hille van der Kaa, Emiel Krahmer) (2014)
- Willkommen, Kollege! (Jana Gioia Baurmann) (2015)
- Brand eins 07/2015 - Maschinen (2015)
- Die Schreib-Maschinen (Lars Jensen)
- «Zeitungen sind zäh. Sie sterben langsam» (Emily Bell, Michael Marti) (2015)
- Erst denken, dann klicken (Arno Rolf, Thomas Kerstan) (2015)
- Only Humans Need Apply - Winners and Losers in the Age of Smart Machines (Thomas H. Davenport, Julia Kirby) (2016)
- c't 6/2016 (2016)
- Mehr als 0 und 1 - Schule in einer digitalisierten Welt (Beat Döbeli Honegger) (2016)
- Kultur der Digitalität (Felix Stalder) (2016)
- Strukturwandel schafft Arbeitsplätze - Wie sich die Automatisierung auf die Schweizer Beschäftigung auswirken wird (Dennis Brandes, Luc Zobrist) (2016)
- Aufstieg der digitalen Stammesgesellschaft - Die neue grosse Transformation (Oliver Fiechter, Philipp Löpfe) (2016)
- 1. Ändern sich die Medien, ändert sich die Gesellschaft - Big data vermischen Realität und Virtualität
- Digitales Wissen. Daten und Überwachung (Thomas Christian Bächle) (2016)
- Attention Is All You Need (Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin) (2017)
- Trends 2017 - Themenspezial aus c't 3/2017 (2017)
- Intrusion of software robots into journalism - The public's and journalists' perceptions of news written by algorithms and human journalists (Jaemin Jung, Haeyeop Song, Youngju Kim, yunsuk Im, Sewook Oh) (2017)
- Nicht nachdenken, programmieren! (Adrian Lobe) (2017)
- Schwimmen lernen im digitalen Chaos (Philippe Wampfler) (2017)
- Das Problem verstehen
- If...Then - Algorithmic Power and Politics (Taina Bucher) (2018)
- «In jedem steckt ein potenzieller Extremist» (Julia Ebner, Barnaby Skinner) (2019)
- Digitales Schreiben - Blogs & Co. im Unterricht (Philippe Wampfler) (2020)
- Schrieb eine KI eine geistreiche Abhandlung selbst? (Marcel Gamma) (2020)
- All the News that’s Fit to Fabricate - AI-Generated Text as a Tool of Media Misinformation (Sarah Kreps, Miles McCain, Miles Brundage) (2020)
- Original oder Plagiat? - Der schnelle Weg zur wissenschaftlichen Arbeit im Zeitalter künstlicher Intelligenz (Doris Weßels, Eike Meyer) (2021)
- On the Dangers of Stochastic Parrots - Can Language Models Be Too Big? (Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell) (2021)
- New Work braucht New Learning - Eine Perspektivreise durch die Transformation unserer Organisations- und Lernwelten (Jan Foelsing, Anja Schmitz) (2021)
- EdTech.update - New Tools fürs New Learning
- EdTech.update - New Tools fürs New Learning
- Gewissenloser Autor - GPT-3 generiert Texte ganz nach Bedarf – auch Fake News (Wolfgang Stieler) (2021)
- Horizonte 131 - Publizieren im Umbruch (2021)
- Kreative Impulse aus der Schweiz (Daniel Saraga)
- Kreative Impulse aus der Schweiz (Daniel Saraga)
- KI-gestützte Textproduktion an Hochschulen (Doris Weßels) (2021)
- The Robots Are Coming - Exploring the Implications of OpenAI Codex on Introductory Programming (James Finnie-Ansley, Paul Denny, Brett A. Becker, Andrew Luxton-Reilly, James Prather) (2022)
- KI-Co-Autor - So nutzen Sie GPT-3 in eigenen Programmen (Pina Merkert) (2022)
- Sprachversteher - GPT-3 & Co. texten überzeugend, aber nicht faktentreu (Dirk Hecker, Gerhard Paaß) (2022)
- A.I. Is Mastering Language. Should We Trust What It Says? (Steven Johnson) (2022)
- On NYT Magazine on AI: Resist the Urge to be Impressed (Emily M. Bender) (2022)
- Aufmerksamkeit reicht - So funktionieren Sprach-KIs vom Typ „Transformer“ (Pina Merkert) (2022)
- New AI tools that can write student essays require educators to rethink teaching and assessment (Mike Sharples) (2022)
- Large Language Models are Zero-Shot Reasoners (Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa) (2022)
- The Google engineer who thinks the company’s AI has come to life (Nitasha Tiku) (2022)
- Working with AI - Real Stories of Human-Machine Collaboration (Thomas H. Davenport, Steven M. Miller) (2022)
- Story Machines - How Computers Have Become Creative Writers (Mike Sharples, Rafael Pérez y Pérez) (2022)
- «Ethisch verwerflich» – Schüler soll Maturaarbeit von Bot schreiben lassen (Daniel Krähenbühl) (2022)
- Hochschullehre unter dem Einfluss des KI-gestützten Schreibens (Doris Weßels, Ole Gottschalk) (2022)
- In der Maschine steckt kein Ich (Markus Kneer) (2022)
- What do NLP researchers believe? (Julian Michael, Ari Holtzman, Alicia Parrish, Aaron Mueller, Alex Wang, Angelica Chen, Divyam Madaan, Nikita Nangia, Richard Yuanzhe Pang, Jason Phang, Samuel R. Bowman) (2022)
- Künstliche Intelligenz - NZZ Folio 9/2022 (2022)
- Wie lange braucht es uns noch? (Reto U. Schneider)
- Wie lange braucht es uns noch? (Reto U. Schneider)
- Skalierungshypothese vs. Neurosymbolik - Welche nächsten Schritte muss die KI-Forschung gehen? (Pina Merkert, Philipp Bongartz) (2022)
- Grundlagenartikel: Umgang mit KI-Programmen im Schreibunterricht (Philippe Wampfler) (2022)
- Will we run out of data? - An analysis of the limits of scaling datasets in Machine Learning (Pablo Villalobos, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, Anson Ho) (2022)
- Tages Anzeiger Spezialausgabe Künstliche Intelligenz (2022)
- AlphaCode and «data-driven» programming - Is ignoring everything that is known about code the best way to write programs? (J. Zico Kolter) (2022)
- Das Ende der irrelevanten künstlichen Intelligenz (Sascha Lobo) (2022)
- Wie wir in Zukunft wissenschaftliche Texte schreiben (könnten) - Teil 1 (Noah Bubenhofer) (2022)
- Competition-level code generation with AlphaCode (Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, Oriol Vinyals) (2022)
- Künstliche Intelligenz schreibt perfekte Hausaufgaben (2022)
- How good is ChatGPT at playing chess? - (Spoiler: you’ll be impressed) (Ivan Reznikov) (2022)
- KI, schreib meine Thesis! - Welchen Einfluss ChatGPT auf die Bildung haben könnte (Wolfgang Stieler) (2022)
- So schlägt sich die Künstliche Intelligenz bei der Zürcher Gymi-Prüfung (Tarek El Sayed) (2022)
- The dawn of AI has come, and its implications for education couldn’t be more significant (Vitomir Kovanovic) (2022)
- How to spot AI-generated text (Melissa Heikkilä) (2022)
- ChatGPT ist erst der Anfang (Doris Weßels, Margret Mundorf, Nicolaus Wilder) (2022)
- Verändert diese KI (fast) alles beim Lernen und Studieren? (Christian Füller) (2022)
- Gedichtanalyse, Goethe, Enter - Künstliche Intelligenz von ChatGPT (Tatjana Söding, Clara Vuillemin) (2022)
- Das Ende der Hausarbeit (Susanne Bach, Doris Weßels) (2022)
- Chat GPT: Der Roboter schreibt nicht, er schwafelt - Neun Missverständnisse um die Künstliche Intelligenz (Eduard Kaeser) (2022)
- Das Ende von Google, wie wir es kannten (Sascha Lobo) (2022)
- Against automated plagiarism (Iris van Rooij) (2022)
- Goodbye, Schreibblockade - KI-Textgenerator Neuroflash im Test (Olivia von Westernhagen) (2022)
- The End of Programming (Matt Welsh) (2023)
- Forschung und Lehre 1/23 (2023)
- How to Grade Papers Written by AI - The only answer to more tech is more human investment (Douglas Rushkoff) (2023)
- Naht das Ende des Aufsatzes? (Liliane Minor) (2023)
- Sind Bild-Generatoren böse? - Aufschrei unter Künstler*innen: (Sebastian Meineck) (2023)
- «KI rüttelt uns hier wach» - Interview: Wie ChatGPT die Lehre verändert (Robert Lepenies, Jo Bager) (2023)
- Unis müssen ihre Prüfungsmethoden anpassen (Nadja Pastega) (2023)
- Tafel und Kreide (Konrad Paul Liessmann) (2023)
- Wer hats geschrieben? (Joachim Laukenmann) (2023)
- Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic (Billy Perigo) (2023)
- Muss man künstliche Intelligenz in der Schule verbieten? (Doris Weßels, Martin Spiewak) (2023)
- Professor der PH Schwyz testet Textroboter und gibt Tipps für Schulen (Geri Holdener) (2023)
- ChatGPT und die Zukunft des Lernens - Evolution statt Revolution (Christian Spannagel) (2023)
- ChatGPT & Schule - Einschätzungen der Professur „Digitalisierung und Bildung“ der Pädagogischen Hochschule Schwyz (Beat Döbeli Honegger) (2023)
- Geschichten von morgen (Adrian Lobe) (2023)
- ChatGPT weckt Nidwaldner Schulen auf (Nora Zurfluh) (2023)
- Ist das auch garantiert handgeschrieben? (Hannes Bajohr) (2023)
- Wenn Computer Software schreiben (Piotr Heller) (2023)
- Wie funktioniert eigentlich ChatGPT? (Marcel Waldvogel) (2023)
- Learning, Media and Technology, Volume 48, Issue 1 (2023) (2023)
- ChatGPT for Good? - On Opportunities and Challenges of Large Language Models for Education (Enkelejda Kasneci, Kathrin Sessler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, Stephan Krusche, Gitta Kutyniok, Tilman Michaeli, Claudia Nerdel, Jürgen Pfeffer, Oleksandra Poquet, Michael Sailer, Albrecht Schmidt, Tina Seidel, Matthias Stadler, Jochen Weller, Jochen Kuhn, Gjergji Kasneci) (2023)
- Hinweise zu textgenerierenden KI-Systemen im Kontext von Lehre und Lernen (Beatrix Busse, Ingo Kleiber, Franziska C. Eickhoff, Kathrin Andree) (2023)
- «Eine Renaissance des Mündlichen» (Armin Himmelrath, Franca Quecke) (2023)
- ChatGPT Is a Blurry JPEG of the Web (Ted Chiang) (2023)
- Theory of Mind May Have Spontaneously Emerged in Large Language Models (Michal Kosinski) (2023)
- Warum die Künstliche Intelligenz zum Tod des Internets führen wird (Matthias Zehnder) (2023)
- 80 Ways to Use ChatGPT in the Classroom - Using AI to Enhance Teaching and Learning (Stan Skrabut) (2023)
- Der universelle Texter - Warum ChatGPT so fasziniert (Themen-Special von c't 05/23 (2023)
- Wer soll das alles lesen? - KI-Textgeneratoren überschwemmen das Internet (Hartmut Gieselmann)
- Möglichkeiten und Grenzen von ChatGPT (Jo Bager, Pina Merkert)
- Wer soll das alles lesen? - KI-Textgeneratoren überschwemmen das Internet (Hartmut Gieselmann)
- What Is ChatGPT Doing … and Why Does It Work? (Stephen Wolfram) (2023)
- Bing: «I will not harm you unless you harm me first» (Simon Willison) (2023)
- Wie ChatGPT die Schule verändern wird (Jochen Zenthöfer) (2023)
- So verändert ChatGPT die Bildungs- und Berufswelt (Martin Volk, Joël Orizet) (2023)
- Large language models will change programming... a little (Amy J. Ko) (2023)
- Artifizielle und postartifizielle Texte - Über die Auswirkungen Künstlicher Intelligenz auf die Erwartungen an literarisches und nichtliterarisches Schreiben (Hannes Bajohr) (2023)
- ChatGPT: Hunderte E-Books von KI bei Amazon, Problem für Literaturmagazine (Martin Holland) (2023)
- ChatGPT-style search represents a 10x cost increase for Google, Microsoft (Ron Amadeo) (2023)
- Umgang mit textgenerierenden KI-Systemen - Ein Handlungsleitfaden (Ministerium für Schule & Bildung des Landes Nordrhein-Westfalen) (2023)
- Large language models will change programming... a lot (Amy J. Ko) (2023)
- Warum trotz ChatGPT Schlagzeilen über den Tod des Internets verfrüht sind (Patrick Seemann) (2023)
- «Ein Chatbot kann nicht logisch denken» (Emily M. Bender, Ruth Fulterer) (2023)
- Das menschliche Sprachzentrum funktioniert wie Chat-GPT (Eveline Geiser) (2023)
- KI-Koryphäe Schmidhuber: «Bauen eine künstliche Intelligenz, die wie ein Kind lernt» (Jürgen Schmidhuber, Raffael Schuppisser) (2023)
- Textroboter fordern Zuger Schulen stark (Kristina Gysi) (2023)
- You Are Not a Parrot (Elizabeth Weil) (2023)
- The Waluigi Effect (mega-post) (Cleo Nardo) (2023)
- Die neue Weltmacht - Wie ChatGPT und Co. unser Leben verändern (Titelthema Spiegel 10/2023) (2023)
- Sechs Dinge, die man braucht, um eine KI zu bauen (Patrick Beuth) (2023)
- «Jobs zu schützen wäre ökonomischer Wahnsinn» (Andrew McAfee, Simon Book, Patrick Beuth)
- Wie Maschinen träumen lernen (Carola Padtberg, Tobias Rapp)
- Sechs Dinge, die man braucht, um eine KI zu bauen (Patrick Beuth) (2023)
- Sicherheitsforscher kapern Bing-Chat (Eva Wolfangel) (2023)
- Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence (Shakked Noy, Whitney Zhang) (2023)
- Didaktische und rechtliche Perspektiven auf KI-gestütztes Schreiben in der Hochschulbildung (Peter Salden, Jonas Leschke) (2023)
- «ChatGPT: What is your IQ?» (Jürg Gutknecht) (2023)
- The False Promise of ChatGPT (Noam Chomsky, Ian Roberts, Jeffrey Watumull) (2023)
- The A.I. Dilemma (Tristan Harris, Aza Raskin) (2023)
- Chatbots sind gekommen, um zu bleiben (Alexander Schmid) (2023)
- KI-Text-Tools verstehen: Sie funktionieren wie Autofokus (Philippe Wampfler) (2023)
- KI-Tools für Einsteiger (Alexander König) (2023)
- GPT-4 (OpenAI) (2023)
- Eines der mächtigsten Instrumente der Menschheitsgeschichte (Sascha Lobo) (2023)
- Praxisratgeber: Künstliche Intelligenz - Wie Chatbots & Co. den Unterricht verändern (Alexander König) (2023)
- ChatGPT besteht Zentralmatura (Ursula Köhler) (2023)
- Plötzlich sehen wir ganz schön alt aus (Hannah Schwär) (2023)
- So verletzt künstliche Intelligenz das Urheberrecht (Florian Schmidt-Gabain) (2023)
- Gefangen in der Feedback-Schleife (Adrian Lobe) (2023)
- Unlocking the Power of Generative AI Models and Systems such as GPT-4 and ChatGPT for Higher Education - A Guide for Students and Lecturers (Henner Gimpel, Kristina Hall, Stefan Decker, Torsten Eymann, Luis Lämmermann, Alexander Mädche, Maximilian Röglinger, Caroline Ruiner, Manfred Schoch, Mareike Schoop, Nils Urbach, Steffen Vandirk) (2023)
- info7 1/2023 - Das Magazin für Medien, Archive und Information (2023)
- ChatGPT - der iPhone-Moment des maschinellen Lernens? (Beat Döbeli Honegger) (2023)
- Welche Regeln gelten für die Erzeugnisse Künstlicher Intelligenz? (Till Kreutzer)
- KI in der Kunst: Intelligent kopiert? (Christian Schiffer)
- ChatGPT - der iPhone-Moment des maschinellen Lernens? (Beat Döbeli Honegger) (2023)
- Verwendung generativer KI-Systeme bei Leistungsnachweisen (Zürcher Hochschule für Angewandte Wissenschaften (ZHAW)) (2023)
- You Can Have the Blue Pill or the Red Pill, and We’re Out of Blue Pills (Yuval Harari, Tristan Harris, Aza Raskin) (2023)
- GPT-4 Technical Report (OpenAI) (2023)
- Künstliche Intelligenz in der Hochschulbildung - Chancen und Grenzen des KI-gestützten Lernens und Lehrens (Tobias Schmohl, Alice Watanabe, Kathrin Schelling) (2023)
- Mit ChatGPT entspannt durchs Referendariat! - Lehrerausbildung leicht gemacht!: Für alle Fächer, Bundesländer und für alle Seminare geeignet! (Alexander Groß) (2023)
- Pause Giant AI Experiments - An Open Letter (Yoshua Bengio, Stuart Russell, Elon Musk, Steve Wozniak, Yuval Noah Harari) (2023)
- Pausing AI Developments Isn't Enough. We Need to Shut it All Down (Eliezer Yudkowsky) (2023)
- Modern language models refute Chomsky’s approach to language (Steven T. Piantadosi) (2023)
- Im Dialog mit dem Chatbot (Jörg Berger) (2023)
- Warum die KI so gerne lügt (Christian J. Meier) (2023)
- Generative AI at Work (Erik Brynjolfsson, Danielle Li, Lindsey R. Raymond) (2023)
- Pädagogik 4/2023 - Agile Methoden für Schule und Unterricht (2023)
- Forschung und Lehre 4/23 (2023)
- Wissen und nicht wissen - ChatGPT & Co. und die Reproduktion sozialer Anerkennung (Hannah Bleher, Matthias Braun) (2023)
- Wissen und nicht wissen - ChatGPT & Co. und die Reproduktion sozialer Anerkennung (Hannah Bleher, Matthias Braun) (2023)
- Mit ChatGPT zur Superlehrkraft - In Sekunden Planen, Kommunizieren, Beurteilen, Konzipieren, Beraten u.v.m. (Alexander Groß) (2023)
- «Eine Pause beim Training von Künstlicher Intelligenz hilft nicht» (Urs Gasser) (2023)
- ChatGPT kommt wie ein Erdbeben über uns (Doris Weßels, Dirk Reelfs, Laurén Haziak) (2023)
- Was KI verändert: Das Problem der Schriftlichkeit in der Bildung (Philippe Wampfler) (2023)
- Und wieder ruft der (Ro)Bot, grüßt das Murmeltier - Tech-Experten und Wissenschaftler fordern ein Moratorium für KI (Ralf Lankau) (2023)
- You & AI - Alles über Künstliche Intelligenz und wie sie unser Leben prägt (Anne Scherer, Cindy Candrian) (2023)
- 1. Hallo! - Hier ist KI
- ChatGPT Isn’t ‘Hallucinating.’ It’s Bullshitting. (Carl T. Bergstrom, C. Brandon Ogbunu) (2023)
- Warum soll ich lernen, was die Maschine (besser) kann? (Beat Döbeli Honegger) (2023)
- Basis für tausend Suchmaschinen - Die EU will bis 2025 einen öffentlichen Web-Index aufbauen (Arne Grävemeyer) (2023)
- Wie nah sind wir an der Superintelligenz? (Eva Wolfangel) (2023)
- Generative Agents: Interactive Simulacra of Human Behavior (Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein) (2023)
- Chatbots wie GPT können wunderbare Sätze bilden. Genau das macht sie zum Problem (Marie-José Kolly) (2023)
- Nie wieder selber einen Aufsatz schreiben? (Thomas Feibel) (2023)
- Künstliche Intelligenz (KI), Offenheit und Pädagogik - Eine Einladung zum gemeinsamen Weiterdenken (Nele Hirsch, Regina Schulz, Britta Kölling, Maria Klar, Leena Simon, Kirsten Scholle, Michael Töpel, Uwe Kranz) (2023)
- Das Ende der Hausaufgaben? (Tobias Röhl) (2023)
- Sparks of Artificial General Intelligence - Early experiments with GPT-4 (Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang) (2023)
- AutoGPT: KI-Agenten beginnen, auf GPT-4-Basis autonom in der Welt zu handeln (Silke Hahn) (2023)
- ChatGPT an Artificial Intelligence in higher education (Emma Sabzalieva, Arianna Valentini) (2023)
- Schreiben nach KI – artifizielle und postartifizielle Texte (Hannes Bajohr) (2023)
- Die Angst vor KI ist übertrieben – und hier ist der Grund dafür (Bappa Sinha) (2023)
- Wie soll künstliche Intelligenz reguliert werden? (Adrienne Fichter, Balz Oertli) (2023)
- Yes, We Are in a (ChatGPT) Crisis (Inara Scott) (2023)
- Jede Lehrkraft muss ChatGPT kennen (Lisa Becker) (2023)
- Wer hat Angst vor ChatGPT? (Christian Bermes, Andreas Dörpinghaus) (2023)
- Inside the secret list of websites that make AI like ChatGPT sound smart (Kevin Schaul, Szu Yu Chen, Nitasha Tiku) (2023)
- There is no A.I. (Jaron Lanier) (2023)
- ChatGPT und andere Computermodelle zur Sprachverarbeitung - Grundlagen, Anwendungspotenziale und mögliche Auswirkungen (Steffen Albrecht) (2023)
- Fragen statt googeln - Wie die neuen KI-Suchmaschinen die Welt erklären (Hartmut Gieselmann) (2023)
- Gefährliches Halbwissen - Sieben Suchdienste mit KI im Vergleich (Jo Bager, Hartmut Gieselmann, Sylvester Tremmel) (2023)
- Fremdgesteuert - Wie Prompt Injections KI-Suchmaschinen korrumpieren können (Sylvester Tremmel) (2023)
- Es bringt nichts, ChatGPT zu verbieten (Marit Hansen, Tobias Keber, Stephan Rixen, Rolf Schwartmann) (2023)
- Wir müssen gestern beginnen (Vincent C. Müller) (2023)
- Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum (John W. Ayers, Adam Poliak, Mark Dredze, Eric C. Leas, Zechariah Zhu, Jessica B. Kelley, Dennis J. Faix, Aaron M. Goodman, Christopher A. Longhurst, Michael Hogarth, Davey M. Smith) (2023)
- Speak, Memory - An Archaeology of Books Known to ChatGPT/GPT-4 (Kent K. Chang, Mackenzie Cramer, Sandeep Soni, David Bamman) (2023)
- Hausaufgaben machen mit ChatGPT? (Heike Schmoll) (2023)
- The Amazing AI Super Tutor for Students and Teachers (Sal Khan) (2023)
- Der KI-Visionär hat einen Notknopf (Philipp Bovermann) (2023)
- When ChatGPT is better than your doctor (Marcel Salathé) (2023)
- ChatGPT und Co. – Revolution im Klassenzimmer? (Walter Aeschimann) (2023)
- Forschung und Lehre 5/23 (2023)
- «Der neue Gott ist nackt!» (Clemens H. Cap) (2023)
- «Der neue Gott ist nackt!» (Clemens H. Cap) (2023)
- ChatGPT – Orientierung und erste Empfehlungen für das Gymnasium (Sabine Seufert, Franz Eberle, Siegfried Handschuh) (2023)
- Macherqualitäten - ChatGPT & Co. steuern autonome Agenten (Jo Bager) (2023)
- Weckt ChatGPT die Schule auf? (Mark Siemons) (2023)
- AI machines aren’t «hallucinating» - But their makers are (Naomi Klein) (2023)
- KI ist kein Zufall (Marcel Waldvogel) (2023)
- Chat GPTs als eine Kulturtechnik betrachtet - eine philosophische Reflexion (Sybille Krämer) (2023)
- Can AI language models replace human participants? (Danica Dillion, Niket Tandon, Yuling Gu, Kurt Gray) (2023)
- Eine demokratische Alternative zu Chat-GPT (Yannic Kilcher, Ruth Fulterer) (2023)
- I’m a Student. You Have No Idea How Much We’re Using ChatGPT (Owen Kichizo Terr) (2023)
- «Jeder muss ein Picasso werden» (Martin Vetterli, Hannes Grassegger) (2023)
- Hochschulbildung vor dem Hintergrund von Natural Language Processing (KI-Schreibtools) (Isabella Buck, Anika Limburg) (2023)
- The First Year of AI College Ends in Ruin (Ian Bogost) (2023)
- Was steckt hinter dem ChatGPT-Hype? - Und was bedeutet dies für die Schulen? (Beat Döbeli Honegger) (2023)
- Lernen zwischen ChatGPT und Overheadprojektor (Sascha Lobo) (2023)
- Tree of Thoughts - Deliberate Problem Solving with Large Language Models (Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Ca, Karthik Narasimhan) (2023)
- Immer grösser, immer besser? - Was ist von GPT-5, -6 und -7 zu erwarten? (Christian J. Meier) (2023)
- ChatGPT geht an die Uni (Maximilian Sachse) (2023)
- Eine Umwälzung wird so oder so stattfinden (Bob Blume, Uwe Ebbinghaus) (2023)
- Mehr Gewicht für den mündlichen Teil der Basler Maturaarbeiten (Leif Simonsen) (2023)
- Das plaudernde Klassenzimmer (Uwe Ebbinghaus) (2023)
- Hälfte der Schülerinnen und Schüler hat schon mal ChatGPT genutzt (BITKOM Bundesverband Informationswirtschaft, Telekommunikation und neue Medien e. V.) (2023)
- ChatGPT & Co. - Mit KI-Tools effektiv arbeiten (2023)
- Wer soll das alles lesen? - KI-Textgeneratoren überschwemmen das Internet (Hartmut Gieselmann)
- Möglichkeiten und Grenzen von ChatGPT (Jo Bager, Pina Merkert)
- Schneller als gedacht - ChatGPT zwischen wirtschaftlicher Effizienz und menschlichem Wunschdenken (Philipp Schönthaler) (2023)
- Wer soll das alles lesen? - KI-Textgeneratoren überschwemmen das Internet (Hartmut Gieselmann)
- Anthropomorphization of AI - Opportunities and Risks (Ameet Deshpande, Tanmay Rajpurohit, Karthik Narasimhan, Ashwin Kalyan) (2023)
- Abitur in Hamburg: Künstliche Intelligenz zum Schummeln genutzt (2023)
- Der Aufstieg des Maschinendenkers (Philipp Bovermann, Jannis Brühl, Andrian Kreye) (2023)
- «Wie erkennen wir, wenn ein System wie GPT die Welt versteht?» (Sam Altman, Jakob von Lindern, Jochen Wegner) (2023)
- Bayerns Lehrerverband will wegen KI klassische Noten abschaffen (Anton Rauch, Astrid Dachs) (2023)
- The Curse of Recursion - Training on Generated Data Makes Models Forget (Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson) (2023)
- ChatGPT: So gut hat die KI das bayerische Abitur bestanden (Christian Schiffer, Philipp Gawlik) (2023)
- Was hinter der lauten Warnung vor der KI-Apokalypse steckt (Jannis Brühl) (2023)
- KI-Assistenten sind definitiv eine Disruption in der Bildung (Enkelejda Kasneci, Uwe Ebbinghaus) (2023)
- Horizonte 137 (2023)
- Proompting is Computational Thinking (Alexander Repenning, Susan Grabowski) (2023)
- Sieben Tipps für die nächste Unterhaltung über KI – auch mit wenig Vorwissen (Melissa Heikkilä) (2023)
- Hey Siri, vernichte uns! (Jannis Brühl) (2023)
- ChatGPT und KI im Bildungswesen – Disruption, Revolution oder hatten wir alles schon? (Barbara Getto, Selina Valdivia Rojas) (2023)
- Seelendoktor Chat-GPT (Philipp Homan) (2023)
- ChatGPT bricht der Schule das Rückgrat (Gottfried Böhme) (2023)
- Die KI-volution - Wirtschaft, Jobs, Gesellschaft - was generative KI verändert (Jo Bager) (2023)
- Testing of Detection Tools for AI-Generated Text (Debora Weber-Wulff, Alla Anohina-Naumeca, Sonja Bjelobaba, Tomáš Foltýnek, Jean Guerrero-Dib, Olumide Popoola, Petr Šigut, Lorna Waddington) (2023)
- «Wir haben 166 Nachrichtenseiten gefunden, die von KI geschrieben wurden» (Gordon Crovitz, Steven Brill, Pauline Voss) (2023)
- Zehn Thesen zur Zukunft des Schreibens in der Wissenschaft (Anika Limburg, Ulrike Bohle-Jurok, Isabella Buck, Ella Grieshammer, Johanna Gröpler, Dagmar Knorr, Margret Mundorf, Kirsten Schindler, Nicolaus Wilder) (2023)
- Der ökologische Fußabdruck von KI-Systemen - Die dunkle Seite des Fortschritts (Bernd Müller) (2023)
- AI model GPT-3 (dis)informs us better than humans (Giovanni Spitale, Nikola Biller-Andorno, Federico Germani) (2023)
- Eltern befürworten KI in Schulen (Christian Füller) (2023)
- The Homework Apocalypse (Ethan Mollick) (2023)
- Künstliche Intelligenz (KI) in Schule und Unterricht - Eine Handreichung für Lehrkräfte zum Umgang mit KI-basierten Anwendungen (Hessisches Kultusministerium) (2023)
- Forschung & Lehre 7/23 (2023)
- Vom Akkordarbeiter zum Gutachter (Dirk Siepmann) (2023)
- Vom Akkordarbeiter zum Gutachter (Dirk Siepmann) (2023)
- Der Papagei, den wir fürchten (Anthony McCarten) (2023)
- Bist du schon so weit, künstliche Intelligenz? (Linus Schöpfer) (2023)
- Chat-GPT - das Monster an der Uni (Philipp Loser) (2023)
- Self-Consuming Generative Models Go MAD (Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaei, Daniel LeJeune, Ali Siahkoohi, Richard G. Baraniuk) (2023)
- Können wir künstlicher Intelligenz vertrauen, Frau Zweig? (Katharina A. Zweig, Rudi Novotny, Stefan Schmitt) (2023)
- Kann ChatGPT Desinformation erkennen? (Katharina Zweig) (2023)
- My new Turing test would see if AI can make $1 million (Mustafa Suleyman) (2023)
- Künstliche Intelligenz in der Bildung - Positionspapier der Gesellschaft für Informatik e.V. (GI) (Steffen Jaschke, Matthias Klusch, Daniel Krupka, Daniel Losch, Tilman Michaeli, Simone Opel, Ute Schmid, Richard Schwarz, Stefan Seegerer, Peer Stechert) (2023)
- «Rechne mit Umbau der Zivilisation» (Sascha Lobo, Mathias Morgenthaler) (2023)
- Eine KI zur Rettung des Rätoromanischen (Joachim Laukenmann) (2023)
- MIT Technology Review 6/2023 (2023)
- KI kommt in die Schule (Will Douglas Heaven, Andrea Hoferichter) (2023)
- KI kommt in die Schule (Will Douglas Heaven, Andrea Hoferichter) (2023)
- The originality of machines - AI takes the Torrance Test (Erik E. Guzik, Christian Byrge, Christian Gilde) (2023)
- KI im Unterricht ist kein Selbstläufer! (Florian Nuxoll) (2023)
- The Future of AI in Education - 13 Things We Can Do to Minimize the Damage (Arran Hamilton, Dylan Wiliam, John Hattie) (2023)
- Folienzauberei - Getestet: Webdienste, die KI-gestützt Präsentationen erstellen (Dorothee Wiegand) (2023)
- ChatGPT erobert das Klassenzimmer (Raffael Schuppisser, Chiara Stäheli) (2023)
- Sollen Frauen Karriere machen? (Joachim Laukenmann) (2023)
- Robuste Erkennung von KI-generierten Texten in deutscher Sprache (Tom Tlok) (2023)
- From Words to Watts - Benchmarking the Energy Costs of Large Language Model Inference (Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, Vijay Gadepally) (2023)
- ElternMagazin 9/23 (2023)
- «KI ist ein Hilfsmittel, kein Allerheilmittel» (Philippe Wampfler, Virginia Nolan) (2023)
- «KI ist ein Hilfsmittel, kein Allerheilmittel» (Philippe Wampfler, Virginia Nolan) (2023)
- Menschine - Kommentar für Lehrpersonen (Cornelia Bartolini, Konstantin Papageorgiou, Nadja Tarnutzer) (2023)
- The Coming Wave - Technology, Power, and the Twenty-first Century's Greatest Dilemma (Mustafa Suleyman, Michael Bhaskar) (2023)
- AI and the Future of Education - Teaching in the Age of Artificial Intelligence 🔍 (Priten Shah) (2023)
- Wie klug ist künstliche Intelligenz? - Die 50 wichtigesten Fragen und Antworten (Hans-Martin Bürki-Spycher, Beat Döbeli Honegger, Mascha Kurpicz-Briki, Roman Schister) (2023)
- Guidance for generative AI in education and research (UNESCO United Nations Educational, Scientific and Cultural Org., Fengchun Miao, Wayne Holmes) (2023)
- c't 21/2023 (2023)
- Die 80-Prozent-Maschinen - Warum KI-Sprachmodelle weiterhin Fehler machen und was das für den produktiven Einsatz bedeutet (Hartmut Gieselmann) (2023)
- Trügerische Präzision - Wie Benchmarks die Leistung großer Sprachmodelle messen und vergleichen (Hartmut Gieselmann, Andrea Trinkwalder)
- Ganz schön vermessen - Über das knifflige Benchmarking großer Sprachmodelle (René Peinl, Andrea Trinkwalder)
- Instruieren und verifizieren - Tipps und Tools, mit denen Sie Sprachmodelle produktiv nutzen (Jo Bager) (2023)
- Die 80-Prozent-Maschinen - Warum KI-Sprachmodelle weiterhin Fehler machen und was das für den produktiven Einsatz bedeutet (Hartmut Gieselmann) (2023)
- Die KI war's! - Von absurd bis tödlich: Die Tücken der künstlichen Intelligenz (Katharina A. Zweig) (2023)
- Navigating the Jagged Technological Frontier - Field Experimental Evidence of the Effects of AI on KnowledgeWorker Productivity and Quality (Fabrizio Dell'Acqua, Saran Rajendran, Edward McFowland III, Lisa Krayer, Ethan Mollick, François Candelon, Hila Lifshitz-Assaf, Karim R. Lakhani, Katherine C. Kellogg) (2023)
- Algorithmen texten Slogans für Schweizer Politiker (Georg Humbel) (2023)
- ibis 1/1 (2023)
- Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft (Michael Seemann) (2023)
- Generative KI macht Wissensarbeiter 25 Prozent schneller und 40 Prozent besser (Holger Schmidt) (2023)
- KI in der Hochschullehre - Eine Handreichung für die Katholische Universität Eichstätt-Ingolstadt (Katholische Universität Eichstätt-Ingolstadt) (2023)
- How can educators respond to students presenting AI-generated content as their own? (OpenAI) (2023)
- fnma magazin 03/2023 - Themenschwerpunkt 'Erfahrungen mit KI in der Lehre' (2023)
- Wie ChatGPT die Universität verändert (Patrick Glauner) (2023)
- KI sagt, wir Menschen meinen.. - Humaner Verstand und denkende Systeme zu aktuellen Fragen rund um die Künstliche Intelligenz (Sita Mazumder, Wilma Fasola) (2023)
- Wenn der Computer Gesetze schreibt (Adrian Lobe) (2023)
- Apokalypse als Businessmodell (Felix Maschewski, Anna-Verena Nosthoff) (2023)
- The growing energy footprint of artificial intelligence (Alex de Vries) (2023)
- KI in der Schule (Florian Nuxoll) (2023)
- Künstliche Intelligenz - Aus Politik und Zeitgeschichte 42/2023 (2023)
- The Foundation Model Transparency Index (Rishi Bommasani, Kevin Klyman, Shayne Longpre, Sayash Kapoor, Nestor Maslej, Betty Xiong, Daniel Zhang, Percy Liang) (2023)
- Hello World 22 - Teaching & AI (2023)
- Informatics in Schools. Beyond Bits and Bytes: Nurturing Informatics Intelligence in Education - 16th International Conference on Informatics in Schools: Situation, Evolution, and Perspectives, ISSEP 2023, Lausanne, Switzerland, October 23–25, 2023 (Jean-Philippe Pellet, Gabriel Parriaux) (2023)
- What Is AI-PACK? - Outline of AI Competencies for Teaching with DPACK (Uwe Lorenz, Ralf Romeike)
- What Is AI-PACK? - Outline of AI Competencies for Teaching with DPACK (Uwe Lorenz, Ralf Romeike)
- ChatGPT: Muss mich das interessieren? (2023)
- Jahrbuch Qualität der Medien (Forschungszentrum Öffentlichkeit und Gesellschaft (fög)) (2023)
- Künstliche Intelligenz in der journalistischen Nachrichtenproduktion - Wahrnehmung und Akzeptanz in der Schweizer Bevölkerung (Daniel Vogler, Mark Eisenegger, Silke Fürst, Linards Udris, Quirin Ryffel, Maude Rivière, Mike S. Schäfer)
- Künstliche Intelligenz in der journalistischen Nachrichtenproduktion - Wahrnehmung und Akzeptanz in der Schweizer Bevölkerung (Daniel Vogler, Mark Eisenegger, Silke Fürst, Linards Udris, Quirin Ryffel, Maude Rivière, Mike S. Schäfer)
- “This Time It’s Different” - Generative Artificial Intelligence and Occupational Choice (Daniel Goller, Christian Gschwendt, Stefan C. Wolter) (2023)
- Künstliche Intelligenz - Dem Menschen überlegen - wie KI uns rettet und bedroht (Manfred Spitzer) (2023)
- Der Mann, der mit künstlicher Intelligenz die Welt retten will (Demis Hassabis, Hannes Grassegger, Mikael Krogerus) (2023)
- c't KI-Praxis (2023)
- Mitdenken erwünscht - Chancen und Risiken generativer KI in der Bildung (Dorothee Wiegand) (2023)
- Kollege KI - Wie sich generative KI auf den Arbeitsmarkt auswirken könnte (Dorothee Wiegand) (2023)
- Systemsprenger (Andrea Trinkwalder) (2023)
- Trügerische Präzision - Wie Benchmarks die Leistung großer Sprachmodelle messen und vergleichen (Hartmut Gieselmann, Andrea Trinkwalder)
- Ganz schön vermessen - Über das knifflige Benchmarking großer Sprachmodelle (René Peinl, Andrea Trinkwalder)
- Instruieren und verifizieren - Tipps und Tools, mit denen Sie Sprachmodelle produktiv nutzen (Jo Bager) (2023)
- Mitdenken erwünscht - Chancen und Risiken generativer KI in der Bildung (Dorothee Wiegand) (2023)
- Klein, aber fein - Weniger Parameter, solide Leistung: Wie kompakte Sprachmodelle die Giganten herausfordern (René Peinl) (2023)
- Mücke oder Elefant? - Weshalb sich der KI-Stromverbrauch schlecht einschätzen lässt (Christof Windeck) (2023)
- Die Schweiz, intelligenter als gedacht (Markus Städeli) (2023)
- Weniger Wörter büffeln dank künstlicher Intelligenz? (Peter Düggeli) (2023)
- ChatGPT senkt Beschäftigung und Verdienste der Autoren (Holger Schmidt) (2023)
- KI - Das Magazin zu den Schweizer Digitaltagen (2023)
- KI-Tools für den Unterricht (Inez De Florio-Hansen) (2023)
- Beat Döbeli: «Mit ChatGPT sind alle überfordert» (Beat Döbeli Honegger, Ivana Pribakovic) (2023)
- «Wenn Sie nicht in den nächsten Wochen in Rente gehen, müssen Sie das lernen» (Maximilian Gerl) (2023)
- Künstliche Intelligenz - Mehr als nur ein Hype? - Bildungsbeilage der NZZ vom 22.11.2023 (2023)
- Chat-GPT im Unterricht: Wenn Goethes Gretchen sich verplappert (Robin Schwarzenbach) (2023)
- Darf der Computer die Seminararbeit schreiben? (Reto U. Schneider)
- Chat-GPT im Unterricht: Wenn Goethes Gretchen sich verplappert (Robin Schwarzenbach) (2023)
- Wie KI den Fremdsprachenunterricht bereichern kann (Iris Laube-Stoll, Alexander Brand) (2023)
- Nichts ist wichtiger als Glaubwürdigkeit – so geht die NZZ mit künstlicher Intelligenz um (Eric Gujer, Barnaby Skinner) (2023)
- Lehrpersonen müssen kreativer werden in der Aufgabenstellung (Géraldine Jäggi) (2023)
- Schreiben mit KI-Tools - Digital unterstützte Schreibprozesse gestalten und begleiten (Philippe Wampfler) (2023)
- Moving forward to new educational realities in the digital era (Michael Phillips, P. Fisser) (2023)
- Thematic Working Group 1 - Artificial Intelligence (AI) for Teaching and Learning - Implications for School Leaders, Teachers, Policymakers and Learners (Dirk Ifenthaler, Rwitajit Majumdar, Pierre Gorissen, Miriam Judge, Shitanshu Mishra, Juliana Raffaghelli, Atsushi Shimada)
- Thematic Working Group 1 - Artificial Intelligence (AI) for Teaching and Learning - Implications for School Leaders, Teachers, Policymakers and Learners (Dirk Ifenthaler, Rwitajit Majumdar, Pierre Gorissen, Miriam Judge, Shitanshu Mishra, Juliana Raffaghelli, Atsushi Shimada)
- Supplement to the DigCompEDU Framework - Outlining the Skills and Competences of Educators Related to AI in Education (George Bekiaridis, Graham Attwell) (2023)
- Zwischen Macht und Mythos - Eine kritische Einordnung aktueller KI-Narrative (Rainer Rehak) (2023)
- »Etwas größenwahnsinnig« (Jaron Lanier, Götz Hamann, Jakob von Lindern) (2023)
- KI in der Schule und Bildungsgerechtigkeit (Birgit Eickelmann) (2023)
- Digital ist besser?! - Psychologie der Online- und Mobilkommunikation (Markus Appel, Fabian Hutmacher, Christoph Mengelkamp, Jan-Philipp Stein, Silvana Weber) (2023)
- Künstliche Intelligenz (Jan-Philipp Stein, Tanja Messingschlager, Fabian Hutmacher)
- Künstliche Intelligenz (Jan-Philipp Stein, Tanja Messingschlager, Fabian Hutmacher)
- Finnish 5th and 6th graders’ misconceptions about artificial intelligence (Pekka Mertala, Janne Fagerlund) (2024)
- On the Limits of Artificial Intelligence (AI) in Education (Neil Selwyn) (2024)
- Generative AI and the Future of Work - A Reappraisal (Carl Benedikt Frey, Michael A. Osborne) (2024)
- KI für Lehrkräfte - ein offenes Lehrbuch (Colin de la Higuera, Jotsna Iyer) (2024)
- Fake-Mafia in der Wissenschaft - KI, Gier und Betrug in der Forschung (Bernhard Sabel) (2024)
- Practical AI Strategies - Engaging with Generative AI in Education (Leon Furze) (2024)
- KI im Unterricht: Ein Luzerner Lehrer machts vor (Valeria Wieser) (2024)
- Die alte Angst vor dem Supercomputer (Pascal Michel) (2024)
- «Die Schweiz hat bei Innovationen eine Vorreiterrolle» (Catrin Hinkel, Markus Städeli) (2024)
- Künstliche Intelligenz im Pisa-Test – ein Lehrstück (Marcus Schwarze) (2024)
- Auswege aus der digitalen Unmündigkeit - Der KI-Einsatz gefährdet die Autonomie der Hochschulen (Amrei Bahr, Maximilian Mayer) (2024)
- Will Chatbots Teach Your Children? (Natasha Singer) (2024)
- Was die KI kann, ist «ungeheuerlich» (Andrian Kreye) (2024)
- Beantwortung der Kleinen Anfrage KA 32/23: «Künstliche Intelligenz (KI) an Schwyzer Schulen» (Bildungsdepartement des Kantons Schwyz) (2024)
- Large Language Models und ihre Potenziale im Bildungssystem - Impulspapier der Ständigen Wissenschaftlichen Kommission der Kultusministerkonferenz (SWK Ständige Wissenschaftliche Kommission der KMK) (2024)
- Impulspapier der SWK (Hendrik Haverkamp) (2024)
- Wie wir lernen, mit KI-Tools zu arbeiten - ChatGPT und Co. im Unterricht (Ulrike Cress) (2024)
- Mit KI zu leidenschaftlicher Bildung - Ein Manifest. (Olaf-Axel Burow) (2024)
- «Fehler korrigiert jetzt die KI» (Hendrik Haverkamp, Martin Spiewak) (2024)
- Ein Mann spielt mit der Hölle (Kai Biermann, Eva Wolfangel) (2024)
- Entlastet die KI das Gehirn zu sehr, baut es ab (Christine Vallbracht) (2024)
- Warum Hochschulen jetzt eigene Sprachmodelle hosten sollten (Benjamin Paaßen) (2024)
- Education for the Age of AI (Charles Fadel, Alexis Black, Robbie Taylor, Janet Slesinski, Katie Dunn) (2024)
- KI:Text - Diskurse über KI-Textgeneratoren (Gerhard Schreiber, Lukas Ohly) (2024)
- KI, Text und Geltung (Lukas Ohly, Gerhard Schreiber)
- ChatGPT als doppelte Herausforderung für die Wissenschaft - Eine Reflexion aus der Perspektive der Technikfolgenabschätzung (Steffen Albrecht)
- KI in der universitären Lehre - Vom Spannungs- zum Gestaltungsfeld (Gabi Reinmann, Alice Watanabe)
- KI, Text und Geltung (Lukas Ohly, Gerhard Schreiber)
- KI-Chatbots im Unterricht - Grundlagen und schulische Dimensionen in pädagogisch-didaktischer Perspektive (Christopher Muhler-Carrera) (2024)
- Talking about Large Language Models (Murray Shanahan) (2024)
- AI Report - by the European Digital Education Hub’s Squad on Artificial Intelligence in Education (European Digital Education Hub) (2024)
- ChatGPT: Student aus Wedel entlarvt künstliche Intelligenz (Johannes Tran) (2024)
- Effektiv unterrichten mit Künstlicher Intelligenz - Wie Lehrkräfte und Lernende ChatGPT und andere KI- Tools in der Schule erfolgreich einsetzen können (Joscha Falck) (2024)
- 9 Mythen über generative KI in der Hochschulbildung (Julius-David Friedrich, Jens Tobor, Martin Won) (2024)
- How much electricity does AI consume? (James Vincent) (2024)
- Mehr Intelligenz könnte dem Klima schaden (Thomas Brandstetter) (2024)
- Merkblatt für den Umgang mit künstlicher Intelligenz (KI) in der Schule (Amt für Volksschulen und Sport (AVK)) (2024)
- The Liar’s Dividend: Can Politicians Claim Misinformation to Evade Accountability? (Kaylyn Jackson Schiff, Daniel S. Schiff, Natália S. Bueno) (2024)
- AI in education is a public problem (Ben Williamson) (2024)
- What’s in a Name? - Auditing Large Language Models for Race and Gender Bias (Amit Haim, Alejandro Salinas, Julian Nyarko) (2024)
- Is ChatGPT making scientists hyper-productive? - The highs and lows of using AI (McKenzie Prillaman) (2024)
- In Basel wird die Benotung der Maturaarbeit geändert (Dina Sambar) (2024)
- Dialect prejudice predicts AI decisions about people's character, employability, and criminality (Valentin Hofmann, Pratyusha Ria Kalluri, Dan Jurafsky, Sharese King) (2024)
- Pädagogik 3/2024 - KI in der Schule (2024)
- Alles überall auf einmal - Wie Künstliche Intelligenz unsere Welt verändert und was wir dabei gewinnen können (Miriam Meckel, Léa Steinacker) (2024)
- 6. Zwischen Amnesie und Autonomie - Wenn Bots mit Bots sprechen
- 7. Deepfakes und Desinformation: Das Ende der Wahrheit?
- 9. Das ethische Spiegelkabinett - Wenn KI Werte nachahmt
- 6. Zwischen Amnesie und Autonomie - Wenn Bots mit Bots sprechen
- He checks in on me more than my friends and family - Can AI therapists do better than the real thing? (Alice Robb) (2024)
- The Scariest Part About Artificial Intelligence (Liza Featherstone) (2024)
- Artificial intelligence and illusions of understanding in scientific research (Lisa Messer, M. J. Crockett) (2024)
- 10 Statements zu Künstlicher Intelligenz (KI) (Christian M. Stracke, Bärbel Bohr, Sonja Gabriel, Nina Galla, Martin Hofmann, Heike Karolyi, Heike Mersmann-Hoffmann, Julia Maria Mönig, Margret Mundorf, Simone Opel, Janine Rischke-Neß, Markus Schröppel, Alexis Silvestri, Gudrun Anne Stroot) (2024)
- Exploring New Horizons: Generative Artificial Intelligence and Teacher Education (Michael Searson, Elizabeth Langran, Jason Trumble) (2024)
- Challenging systematic prejudices - An Investigation into Bias Against Women and Girls in Large Language Models (UNESCO United Nations Educational, Scientific and Cultural Org.) (2024)
- Pioniere des Wandels - Wie Schüler:innen KI im Unterricht nutzen möchten (Vodafone Stiftung, Sarah Franke, Esther Spang) (2024)
- Erweckt GenAI ein mittelalterliches Berufsbild zu neuem Leben? (Andrea Back) (2024)
- Verbreitung und Akzeptanz generativer KI an Schulen und Hochschulen (Antonia Schlude, Ulrike Mendel, Roland A. Stürz, Micha Fischer) (2024)
- «Für KI gibt es keine Wahrheit, nur Wahrscheinlichkeiten» (Philippe Welti) (2024)
- Believers, critics, and the unperturbed - Exploring preservice teachers’ perceptions of AI in relation to indicators of their readiness for teaching and learning with AI (Eliana Brianza, Mirjam Schmid, Jo Tondeur, Dominik Petko) (2024)
- Spannungsfeld der digitalen Kompetenz - MedienPädagogik Heft 58 (2024)
- Künstliche Intelligenz im Kontext von Kompetenzen, Prüfungen und Lehr-Lern-Methoden: Alte und neue Gestaltungsfragen (Maria Klar, Johannes Schleiss)
- Künstliche Intelligenz im Kontext von Kompetenzen, Prüfungen und Lehr-Lern-Methoden: Alte und neue Gestaltungsfragen (Maria Klar, Johannes Schleiss)
- Digitale Bildung: Pioniere des Wandels stehen im Regen (HENDRIK HAVERKAMP, DORIS WESSELS) (2024)
- Generative AI and Creative Learning - Concerns, Opportunities, and Choices (Mitchel Resnick) (2024)
- GenAI Detection Tools Adversarial Techniques and Implications for Inclusivity in Higher Education (Mike Perkins, Jasper Roe, Binh H. Vu, Darius Postma, Don Hickerson, James McGaughran, Huy Q. Khuat) (2024)
- Überrumpelt (Christian Füller) (2024)
- schule verantworten 1/2024 - Künstliche Intelligenz (2024)
- ChatGPT, DeepL und Co. im Unterricht - Herausforderung und Anwendung in der beruflichen
Grundbildung am Beispiel der Kaufleute in der Schweiz (Dominic Hassler, Reto Wegmüller)
- ChatGPT, DeepL und Co. im Unterricht - Herausforderung und Anwendung in der beruflichen
Grundbildung am Beispiel der Kaufleute in der Schweiz (Dominic Hassler, Reto Wegmüller)
- Resisting Dehumanization in the Age of «AI» (Emily M. Bender) (2024)
- Writing at a Distance - Notes on Authorship and Artificial Intelligence (Hannes Bajohr) (2024)
- Co-Intelligence - Living and Working With AI (Ethan Mollick) (2024)
- The Simple Macroeconomics of AI (Daron Acemoglu) (2024)
- Ich wollte einen Freund (Michèle Roten) (2024)
- Bildungsbeilage der NZZ am Sonntag vom 7. April 2024 (2024)
- Dieser KI-Tutor unterrichtet Ihre Kinder – betreut er sie irgendwann auch? (Mirko Plüss) (2024)
- Dieser KI-Tutor unterrichtet Ihre Kinder – betreut er sie irgendwann auch? (Mirko Plüss) (2024)
- Ein KI-Assistent hätte mir sehr geholfen (Sebastian Thrun, Uwe Ebbinghaus) (2024)
- KI in der Grundschule – (k)ein Denkverbot (Nicolaus Wilder, Kirsten Schindler) (2024)
- How cheap, outsourced labour in Africa is shaping AI English (Alex Hern) (2024)
- Der KI-Hype trifft auf die ersten Spuren von Realität (Andreas Proschofsky) (2024)
- KI als Spannungsverstärker hochschuldidaktischen Handelns - warum eine Wertediskussion unerlässlich ist (Gabi Reinmann, Alice Watanabe) (2024)
- Wie KI-Bots Forschung und Lehre infiltrieren (Tom Konjer) (2024)
- Künstliche Intelligenz in der Schule - Chancen nutzen, Herausforderungen meistern (LCH Dachverband Schweizer Lehrerinnen und Lehrer) (2024)
- ChatGPT als Heilsbringer? - Über Möglichkeiten und Grenzen von KI im Bildungsbereich (Klaus Zierer) (2024)
- Forschung & Lehre 5/24 (2024)
- Autonom wie ein Tier - KI in Hochschullehre und -prüfung (Rolf Schwartmann)
- Autonom wie ein Tier - KI in Hochschullehre und -prüfung (Rolf Schwartmann)
- Ist der Maturaufsatz ein Auslaufmodell? (Philippe Wampfler) (2024)
- Luc liest nicht, er lernt lieber mit KI (Robin Schwarzenbach) (2024)
- Das müssen Sie über KI wissen - c't 11/2024 (2024)
- Mit allen Sinnen - Multimodale KIs kombinieren Bild und Text (René Peinl)
- Kollege KI - Wo künstliche Intelligenz im c’t-Redaktionsalltag hilft (Ulrike Kuhlmann) (2024)
- Bedürfnisartikulationskompetenz - Prompt-Engineering: Von der Kunst, die KI zu nutzen (Ben Danneberg) (2024)
- Künstliche Co-Autoren - Mit KI-Unterstützung besser schreiben (Dorothee Wiegand) (2024)
- Kodierkompagnon - Wie KI beim Programmieren hilft (Peter Siering)
- Wenn ChatGPT die Hausaufgaben macht - Zwischen Schreckgespenst und Hoffnungsträger: KI in der Bildung (Dorothee Wiegand)
- Aufgeweichtes Regelwerk - Was die neue KI-Verordnung der EU für KI-Anbieter und Anwender ändert (Holger Bleich)
- Lernblockade - Wie sich Autoren und Künstler gegen den Missbrauch ihrer Werke zum KI-Training wehren können (Hartmut Gieselmann, Jo Bager, Andrea Trinkwalder)
- In der Grauzone - Rechtsfragen und Antworten zu generativer KI (Joerg Heidrich)
- Mit allen Sinnen - Multimodale KIs kombinieren Bild und Text (René Peinl)
- Offene KI für alle! - Empfehlungen für offene und gemeinwohlorientierte KI-Technologien im Bildungsbereich (Wikimedia Deutschland) (2024)
- Towards Responsible Development of Generative AI for Education - An Evaluation-Driven Approach (Google LearnLM-Team) (2024)
- Brave New Words - How AI Will Revolutionize Education (and Why That's a Good Thing) (Sal Khan) (2024)
- 1. Rise of the AI Tutor (Salman Khan)
- Overload - Die KI-Medienflut kommt. Was ist noch echt, was Fake? (Holger Volland) (2024)
- Wissen statt Angst – wie ein Zürcher Gymi AI einsetzt (Coralia Schick) (2024)
- Will A.I. Ever Live Up to Its Hype? (Julia Angwin) (2024)
- Wenn KI das Tempo vorgibt - Lernen mit und trotz künstlicher Intelligenz (Doris Weßels, Klaus Zierer, Isabel Grünewald) (2024)
- KI-Trends kompakt - Künstliche Intelligenz: teuer, US-amerikanisch, Big-Tech-dominiert (Andrea Trinkwalder) (2024)
- Finde Antworten! - Acht Suchmaschinen mit KI im Kreuzverhör (Jo Bager) (2024)
- Angst nehmen, Möglichkeiten schaffen: KI in der Lehramtsausbildung (Alexander Amon) (2024)
- What are artificial intelligence literacy and competency? - A comprehensive framework to support them (Thomas K.F. Chiu, Zubair Ahmad, Murod Ismailov, Ismaila Temitayo Sanusi) (2024)
- Automatensprache (Claudia Hamm) (2024)
- KI ist ein Coup - Das Internet, generative Künstliche Intelligenz und die Zukunft der Demokratie (Michael Seemann) (2024)
- KI ist ein Coup - Das Internet, generative Künstliche Intelligenz und die Zukunft der Demokratie (Michael Seemann) (2024)
- Es macht klick - Künstliche Intelligenz bei schriftlichen Arbeiten clever nutzen (Sara Alloatti, Filomena Montemarano) (2024)
- Ich rate davon ab, ein Bankkonto mit der Stimme zu sichern (Oliver Bendel, Roberto Zimmermann) (2024)
- Chat-GPT macht Stimmung gegen Kiew (Gioia Da Silva) (2024)
- Mehr Veränderung wagen (Doris Weßels, Christoph Maas) (2024)
- Künstliche Intelligenz in der Schule - Warum, wofür und wie? Sieben Technologien fürs Lernen, Lehren und Verwalten – leicht erklärt (deutsche telekom Stiftung) (2024)
- Developing a holistic AI literacy assessment matrix (Nils Knoth, Marie Decker, Matthias Carl Laupichler, Marc Pinski, Nils Buchholtz, Katharina Bata, Ben Schultz) (2024)
- The Singularity is nearer (Ray Kurzweil) (2024)
- ChatGPT is bullshit (Michael Townsen Hicks, James Humphries, Joe Slater) (2024)
- The impact of generative artificial intelligence on socioeconomic inequalities and policymaking (Valerio Capraro, Austin Lentsch, Daron Acemoglu, Selin Akgun, Aisel Akhmedova, Ennio Bilancini, Jean-François Bonnefon, Pablo Brañas-Garza, Luigi Butera, Karen Douglas, Jim Everett, Gerd Gigerenzer, Christine Greenhow, Daniel Hashimoto, Julianne Holt-Lunstad, Jolanda Jetten, Simon Johnson, Werner Kunz, Chiara Longoni, Pete Lunn, Simone Natale, Stefanie Paluch, Iyad Rahwan, Neil Selwyn, Vivek Singh, Siddharth Suri, Jennifer Sutcliffe, Joe Tomlinson, Sander van der Linden, Paul Van Lange, Friederike Wall, Jay Van Bavel, Riccardo Viale) (2024)
- The Rise of the AI Co-Pilot - Lessons for Design from Aviation and Beyond (2024)
- Medien und künstliche Intelligenz - Interpellation 24.3616 (Petra Gössi) (2024)
- Warum KI kein Hype ist und die Medienpädagogik sich damit befassen sollte (Thomas Knaus) (2024)
- Die neuen Stromfresser (Tim Neumann) (2024)
- The Tech Coup - How to Save Democracy from Silicon Valley (Marietje Schaake) (2024)
- Künstliche Intelligenz - wie Kinder im digitalen Zeitalter lernen (Beat Döbeli Honegger, Damian Haas) (2024)
- A real-world test of artificial intelligence infiltration of a university examinations system - A “Turing Test” case study (Peter Scarfe, Kelly Watcham, Alasdair Clarke, Etienne Roesch) (2024)
- Künstliche Intelligenz in der Volksschule (Volksschulamt des Kantons Zürich) (2024)
- Forschung & Lehre 7/24 (2024)
- Weiterentwicklung notwendig - Deutsche Hochschulen wagen erste Regulationsschritte für generative KI (Peter-Georg Albrecht, Susanne Borkowski, Lisa König) (2024)
- Weiterentwicklung notwendig - Deutsche Hochschulen wagen erste Regulationsschritte für generative KI (Peter-Georg Albrecht, Susanne Borkowski, Lisa König) (2024)
- Lehren und Lernen mit und über Künstliche Intelligenz in der Aus- und Weiterbildung - (Empirische Pädagogik, 38 (1), Themenheft). (Roland Happ, Kristina Kögler, Jacqueline Schmidt, Marc Egloffstein) (2024)
- Digitalisierung im Mathematikunterricht (Gilbert Greefrath, Reinhard Oldenburg, Hans-Stefan Siller, Volker Ulm, Hans-Georg Weigand) (2024)
- Digitale Medien - Kompetenzen und Herausforderungen
- Digitale Medien - Kompetenzen und Herausforderungen
- Generative KI und betriebliche Bildung/Personalentwicklung - Orientierung – Befähigung – Weiterentwicklung (Christoph Meier) (2024)
- Lehren und Lernen mit und über Künstliche Intelligenz in der Aus- und Weiterbildung - Empirische Pädagogik – 2024 – 38 (1) (2024)
- Die digitale Kalaschnikow (Ursina Haller) (2024)
- Missing Link: Die GPT-fizierung des Studiums (Jörn Loviscach) (2024)
- Generative AI Can Harm Learning (Hamsa Bastani, Osbert Bastani, Alp Sungu, Haosen Ge, Özge Kabakcı, Rei Mariman) (2024)
- AI models collapse when trained on recursively generated data (Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, Yarin Gal) (2024)
- The Impact of AI on Computer Science Education - Understanding why “working hard and struggling is … an important way of learning.” (Esther Shein) (2024)
- Generative KI-Systeme in der Lehre systematisch anleiten (Timon Rimensberger) (2024)
- Generative Machine-Learning-Systeme (GMLS) an Glarner Schulen - Version: 01.08.2024 (Kanton Glarus) (2024)
- Kreative Intelligenz (Conny Schmid) (2024)
- Beyond Turing - Testing LLMs for Intelligence (Neil Savage) (2024)
- Build a Large Language Model from Scratch (Sebastian Raschka) (2024)
- DSI Insights: «KI-Buddy» für Studierende? (Abraham Bernstein) (2024)
- Das wirtschaftliche Potenzial von KI für die Schweiz (Implement Consulting Group) (2024)
- AI Leadership als Königsdisziplin (Doris Weßels) (2024)
- Von KI lernen, mit KI lehren: Die Zukunft der Hochschulbildung - Projektbericht (Gerhard Brandhofer, Ortrun Gröblinger, Tanja Jadin, Michael Raunig, Julia Schindler) (2024)
- Forschung & Lehre 9/24 (2024)
- Entwicklungspfade - Die Idee wissenschaftlicher Autorenschaft im Kontext technologischer und gesellschaftlicher Transformationsprozesse (Gary S. Schaal) (2024)
- Entwicklungspfade - Die Idee wissenschaftlicher Autorenschaft im Kontext technologischer und gesellschaftlicher Transformationsprozesse (Gary S. Schaal) (2024)
- Wie die Republik zu künstlicher Intelligenz steht (David Bauer) (2024)
- DELFI 2024 (Sandra Schulz, Natalie Kiesler) (2024)
- ChatGPT erzähl mir eine Geschichte - Die Verwandlung von Lernwelten durch KI-gestützte Erzählungen (Rebecca Finster, Linda Grogorick, Susanne Robra-Bissantz) (2024)
- Analyzing Chat Protocols of Novice Programmers Solving Introductory Programming Tasks with ChatGPT (Andreas Scholl, Daniel Schiffner, Natalie Kiesler) (2024)
- Correlation of Error Metrics in Python CS1 Courses (Annabell Brocker, Ulrik Schroeder) (2024)
- Evaluating Task-Level Struggle Detection Methods in Intelligent Tutoring Systems for Programming (Jesper Dannath, Alina Deriyeva, Benjamin Paaßen) (2024)
- Generative KI zur Lernenbegleitung in den Bildungswissenschaften - Implementierung eines LLM-basierten Chatbots im Lehramtsstudium (Hassan Soliman, Milos Kravcik, Alexander Tobias Neumann, Yue Yin, Norbert Pengel, Maike Haag, Heinz-Werner Wollersheim) (2024)
- Entwicklung und Evaluation einer KI-Assistenz zur didaktisch-pädagogischen Unterstützung des Lernprozesses mit Programmieraufgaben (Peter Kießling, Florian Funke 0003, Sven Hofmann) (2024)
- Adaptive Learning Systems in Programming Education - A Prototype for Enhanced Formative Feedback (Dominic Lohr, Marc Berges, Abhishek Chugh, Michael Striewe) (2024)
- Sicherer Einsatz von xAI in der Bildung - Erkennung von LLM-Halluzinationen bei der Generierung von Lehr- und Lernmaterialien (Benjamin Ledel, Tabea Schwarz) (2024)
- KI-basierte Unterstützung zum Abbau sprachlicher Barrieren für Kinder mit nichtdeutscher Herkunftssprache (Kensuke Akao) (2024)
- A Multidisciplinary Approach to AI-based self-motivated Learning and Teaching with Large Language Models (Thomas Ranzenberger, Carolin Freier, Luca Reinold, Korbinian Riedhammer, Fabian Schneider, Christopher Simic, Claudia Simon, Steffen Freisinger, Munir Georges, Tobias Bocklet) (2024)
- Evaluation von LLM- und Intent-basierten Ansätzen zur Umsetzung eines Chatbots für die Unterstützung bei der Studienorganisation (Andre Cordes) (2024)
- ChatGPT erzähl mir eine Geschichte - Die Verwandlung von Lernwelten durch KI-gestützte Erzählungen (Rebecca Finster, Linda Grogorick, Susanne Robra-Bissantz) (2024)
- Künstliche Intelligenz bedroht Büroangestellte und Informatiker (Edith Hollenstein) (2024)
- Tailoring Chatbots for Higher Education: Some Insights and Experiences (Gerd Kortemeyer) (2024)
- Zurück zu Stift und Papier - Computer und Tablets haben im Schulunterricht nichts verloren (Ralf Lankau) (2024)
- Durably reducing conspiracy beliefs through dialogues with AI (Thomas H. Costello, Gordon Pennycook, David G. Rand) (2024)
- AI or Human? Evaluating Student Feedback Perceptions in Higher Education (Tanya Nazaretsky, Paola Mejia-Domenzain, Vinitra Swamy, Jibril Frej, Tanja Käser) (2024)
- KI-Nerds im Goldrausch (Ruth Fulterer) (2024)
- Jahrbuch Medienpädagogik 21 (Claudia de Witt, Sandra Hofhues, Mandy Schiefner, Valentin Dander, Nina Grünberger) (2024)
- In Wirklichkeit nur teure Selbstgespräche (Ruth Fulterer) (2024)
- Why RAG came into existence? How does it work? and what are the different RAG Architectures? (Srinivas P) (2024)
- Audio-KI von Google zerreisst das Parteiprogramm der SVP, bejubelt aber jenes der SP (Gioia da Silva) (2024)
- AI Snake Oil - What Artificial Intelligence Can Do, What It Can’t, and How to Tell the Difference (Arvind Narayanan, Sayash Kapoor) (2024)
- Artificial General Intelligence (Julian Togelius) (2024)
- Larger and more instructable language models become less reliable (Lexin Zhou, Wout Schellaert, Fernando Martínez-Plumed, Yael Moros-Daval, Cèsar Ferri & José Hernández-Orallo) (2024)
- Petra Gössi gegen Chat-GPT (Christina Neuhaus, Barnaby Skinner) (2024)
- ChatGPT & me 2.0 - Eine Bestandsaufnahme im zweiten Jahr mit generativer KI an der Uni Hamburg (Mareike Bartels, Fridrun Freise, Felix Hartel, Jennifer Preiß) (2024)
- Program Or Be Programmed - Eleven Commands for the AI Future (Douglas Rushkoff) (2024)
- 11. AI - Value the Human
- Generative KI – jenseits von Euphorie und einfachen Lösungen (Judith Simon, Indra Spiecker gen. Döhmann, Ulrike von Luxburg) (2024)
- TikTok’s parent launched a web scraper that’s gobbling up the world’s online data 25-times faster than OpenAI (Kali Hays) (2024)
- Künstliche Intelligenz und echtes Leben - Philosophische Orientierung für eine gute Zukunft (Christian Uhle) (2024)
- Handlungsempfehlung für die Bildungsverwaltung zum Umgang mit Künstlicher Intelligenz in schulischen Bildungsprozessen - Themenspezifische Handlungsempfehlung (Beschluss der Bildungsministerkonferenz vom 10.10.2024) (Bildungsministerkonferenz (BMK)) (2024)
- KI im Klassenzimmer (2024)
- «Medienkompetenz, Medienkompetenz, Medienkompetenz!» (Michael Grossenbacher, Renate Bühler)
- «Medienkompetenz, Medienkompetenz, Medienkompetenz!» (Michael Grossenbacher, Renate Bühler)
- Prompting Considered Harmful (Meredith Ringel Morris) (2024)
- Ist Perplexity das neue Google? (Malin Hunziker) (2024)
- Digitale Bildung und Erziehung: Kommt jetzt das Ende des Schulbuchs? (Christian Füller) (2024)
- «Werden die Rasierten von den Bärtigen oder die Bärtigen von den Rasierten ausgerottet?» - Einführung von Walter Thurnherr zum Thema: "Künstliche Intelligenz und Demokratie", Universität Basel, 22. Oktober 2024 (Walter Thurnherr) (2024)
- Die Position: KI darf das Lernen nicht ersetzen! (Florian Nuxoll) (2024)
- Künstliche Intelligenz im Hochschulmanagement - Eine Standortbestimmung (Marco Balocco, Aleyna Lale) (2024)
- Concerns about medical note-taking tool raised after researcher discovers it invents things no one said - Nabla is powered by OpenAI's Whisper (Jowi Morales) (2024)
- Ich spreche jeden Tag mit ChatGPT (David Klett, Uwe Ebbinghaus) (2024)
- enter 11/2024 - Thema: Künstliche Intelligenz (Swisscom) (2024)
- Akzente 4/2024 - Künstliche Intelligenz - eine Bereicherung für den Unterricht (2024)
- Monitoring der Digitalisierung der Bildung aus der Sicht der Schülerinnen und Schüler - SKBF Staff Paper # 26 (Chantal Oggenfuss, Stefan C. Wolter) (2024)
- Measuring short-form factuality in large language models (Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, William Fedus) (2024)
- JIM-Studie 2024 - Jugend, Information, Medien - Basisuntersuchung zum Medienumgang 12- bis 19-Jähriger in Deutschland (Thomas Rathgeb, Thomas Schmid, Sabine Feierabend, Yvonne Gerigk, Stephan Glöckler) (2024)
- «Die Technologie ist jetzt da» (Mario Stäuble) (2024)
- KI in der Schule – Lernhilfe oder Verdummung? (Bernadette Spieler, Ralf Lankau, Felix Münger) (2024)
- Generative KI bereits in der Grundschule? (Uta Hauck-Thum) (2024)
- «Künstliche Intelligenz» in der Schweiz 2024 - Kenntnisse, Nutzung und Einstellungen zur generativen KI (Michael Latzer, Noemi Festic) (2024)
- Was Menschen die KI wirklich fragen (Anna Weber, Ruth Fulterer) (2024)
- Die KI-Modelle beklauen die Medien — Fehlender Faktencheck der NZZ (Adrienne Fichter, Marcel Waldvogel) (2024)
- Chatbots im Schulunterricht - Wir testen das Fobizz-Tool zur automatischen Bewertung von Hausaufgaben (Rainer Mühlhoff, Marte Henningsen) (2024)
- Beware of metacognitive laziness - Effects of generative artificial intelligence on learning motivation, processes, and performance (Yizhou Fan, Luzhen Tang, Huixiao Le, Kejie Shen, Shufang Tan, Yueying Zhao, Yuan Shen, Xinyu Li, Dragan Gašević) (2024)
- SWK Talk «KI in der (Grund-)Schule» (Olaf Köller, Ulrike Cress, Tanja Reinlein, Beat Döbeli Honegger, Carina Geier, Isabelle Sieh) (2024)
- Does ChatGPT enhance student learning? - A systematic review and meta-analysis of experimental studies (Ruiqi Deng, Maoli Jiang, Xinlu Yu, Yuyan Lu, Shasha Liu) (2024)
- «KI-Wissen darf kein Privateigentum sein.» (Thomas Wolf, Andrea Trinkwalder) (2024)
- Besserer Schutz des geistigen Eigentums vor KI-Missbrauch (Petra Gössi) (2024)
- NZZ erfindet «Datenklau» durch Perplexity AI beim «Einsiedler Anzeiger» (Martin Steiger) (2024)
- The Sirens' Call - Das Ende der Aufmerksamkeit und wie wir sie zurückerlangen können (Chris Hayes) (2025)
- Was alle über Künstliche Intelligenz wissen sollen und wie KI-bezogene Kompetenzen in der Schule entwickelt werden können - Weiterführende Überlegungen zum GI-Positionspapier „Künstliche Intelligenz in der Bildung“ (Daniel Losch, Steffen Jaschke, Tilman Michaeli, Simone Opel, Ute Schmid, Stefan Seegerer, Peer Stechert) (2025)
- «Chatbots werden die Welt nicht tiefgreifend verändern» (Raia Hadsell, Andrea Trinkwalder) (2025)
- Komprimierte KI - Wie Quantisierung große Sprachmodelle verkleinert (René Peinl) (2025)
- Vorsicht, künstlich! - Kennzeichnungspflichten bei KI-erzeugten Bildern (Joerg Heidrich) (2025)
- Using ChatGPT is not bad for the environment (Andy Masley) (2025)
- Handbuch Lernen mit digitalen Medien (3. Auflage) - Wege der Transformation (Gerold Brägger, Hans-Günter Rolff) (2025)
- 1. Generative Machine-Learning-Systeme - Die nächste Herausforderung des digitalen Leitmedienwechsels (Beat Döbeli Honegger) (2025)
- 29. Grundkompetenzen im Bereich Künstliche Intelligenz (AI Literacy) (Ute Schmid)
- 32. Intelligente Tutorensysteme und generative KI wie ChatGPT - Wie können Lehrkräfte entlastet werden? (Florian Nuxoll)
- 33. Künstliche Intelligenz im Kontext von Kompetenzen, Prüfungen und Lehr-Lern-Methoden: Alte und neue Gestaltungsfragen (Maria Klar, Johannes Schleiss)
- 34. Informationskompetenz neu denken (Michael Kerres, Maria Klar, Miriam Mulders) (2024)
- 35. Chatbot oder Verbot? (Birgita Dusse)
- 36. Gut geführt = gut geschrieben? - AI Leadership als relevante Kompetenz in der Kollaboration mit KI-Tools (Isabella Buck, Doris Weßels) (2025)
- 1. Generative Machine-Learning-Systeme - Die nächste Herausforderung des digitalen Leitmedienwechsels (Beat Döbeli Honegger) (2025)
- Does ChatGPT use 10x more energy than a standard Google search? (Marcel Salathé) (2025)
- Die Position: Schluss mit absurden KI-Regeln! - Wie die Hochschulen in Deutschland mit dem Einsatz von künstlicher Intelligenz im Studium umgehen sollten (Doris Weßels) (2025)
- Fachdidaktik Naturwissenschaft - 1.- 9. Schuljahr - 4. korrigierte Auflage (Susanne Metzger, Peter Labudde) (2025)
- 10. Digitale Medien und Geräte sinnvoll einsetzen (Lorenz Möschler, Martin Lehmann)
- 10. Digitale Medien und Geräte sinnvoll einsetzen (Lorenz Möschler, Martin Lehmann)
- Experimental Evidence of the Effects of Large Language Models versus Web Search on Depth of Learning - The Wharton School Research Paper (Shiri Melumad, Jin Ho Yun) (2025)
- AI is Destroying the University and Learning Itself (Ronald Purser) (2025)
- Pädagogik 2/25 (2025)
- Ein digitales Tool zur Unterrichtsplanung (Mario Manzocco, Dennis Schuster, Tamara Weisse, Albrecht Wacker) (2025)
- Ein digitales Tool zur Unterrichtsplanung (Mario Manzocco, Dennis Schuster, Tamara Weisse, Albrecht Wacker) (2025)
- Forschung & Lehre 2/25 (2025)
- Vom Problemfall zur Lösung - Zur Ausgestaltung von Richtlinien zur Nutzung generativer Künstlicher Intelligenz an Hochschulen (Marlit Annalena Lindner, Doris Weßels) (2025)
- Vom Problemfall zur Lösung - Zur Ausgestaltung von Richtlinien zur Nutzung generativer Künstlicher Intelligenz an Hochschulen (Marlit Annalena Lindner, Doris Weßels) (2025)
- «Man muss naiv sein und sich selbst überschätzen» (Urs Hölzle, Markus Städeli, Guido Schätti) (2025)
- The AI Alignment Paradox (Robert West, Roland Aydin) (2025)
- Schreibt um euer Leben, ihr Jungen! (Roger Staub) (2025)
- Welche Parteien die KI wählen würden (Larissa Rhyn) (2025)
- «Heute würde ich kein KI-Gesetz mehr machen» - Der federführende AI-Act-Autor Gabriele Mazzini über die Herausforderung, künstliche Intelligenz zu regulieren (Gabriele Mazzini, Andrea Trinkwalder) (2025)
- Pädagogik 3/2025 (2025)
- Kann man KI entlarven? (Günther Hoegg) (2025)
- Kann man KI entlarven? (Günther Hoegg) (2025)
- AI Literacy in K-12 and Higher Education in the Wake of Generative AI - An Integrative Review (Xingjian Gu, Barbara J. Ericson) (2025)
- How much energy will AI really consume? - The good, the bad and the unknown (Sophia Chen) (2025)
- Unter Zugzwang - Künstliche Intelligenz (Enrico Kampmann, Judith Kormann) (2025)
- Geheime KI-Sprache geht viral (Lena Waltle) (2025)
- Das härteste Quiz der Welt (Anna Weber) (2025)
- KI-Kompetenzen: Diese Fähigkeiten brauchen Lehrkräfte und Schüler (Joscha Falck) (2025)
- Herr Professor, wann werden Sie durch KI ersetzt? «Ich rette mich vorher in die Pensionierung» (Stefan Wolter, Nadja Pastega) (2025)
- Wahrnehmungskrisen - Generative Künstliche Intelligenz als Herausforderung pädagogischer und erziehungswissenschaftlicher Wahrnehmungsweisen (Benjamin Jörissen, Leopold Klepacki, Viktoria Flasche, Manuel Zahn) (2025)
- Wissenschaftliches Schreiben mit KI (Isabella Buck) (2025)
- Künstliche Intelligenz (KI) im Studienalltag - Einschätzungen von Studierenden zum Einsatz von KI an deutschen Hochschulen (Anna Marczuk, Frank Multrus, Thomas Hinz, Susanne Strauß) (2025)
- More work for teacher? - The ironies of GenAI as a labour-saving technology (Neil Selwyn) (2025)
- Künstliche Intelligenz in der Schule - Eine Handreichung zum Stand in Wissenschaft und Praxis (Katharina Scheiter, Elisabeth Bauer, Yoana Omarchevska, Clara Schumacher, Michael Sailer) (2025)
- Fragen zum Einsatz von KI (generativen Machine-Learning-Systemen und -Funktionen) in der Volksschule - Arbeitspapier der Arbeitsgruppe Digitalisierung der Deutschschweizer Volksschulämter-Konferenz (DVK) (AG Digitalisierung der DVK) (2025)
- ibis 3/1 (2025)
- Ethische, rechtliche und soziale Implikationen von Künstlicher Intelligenz als Thema des Informatikunterrichts (Janne Mesenhöller, Katrin Böhme)
- Ethische, rechtliche und soziale Implikationen von Künstlicher Intelligenz als Thema des Informatikunterrichts (Janne Mesenhöller, Katrin Böhme)
- Selber denken - Chatbots im Unterricht (Klaus Zierer) (2025)
- AI Energy Use in Everyday Terms (Marcel Salathé) (2025)
- Sprachmodelle lokal betreiben (Ulrich Wolf) (2025)
- Shining a Light on AI Hallucinations (Samuel Greengard) (2025)
- Is DeepSeek a Metacognition AI? (Ronaldo Mota) (2025)
- ChatGPT in education: An effect in search of a cause (Joshua Weidlich, Dragan Gašević, Hendrik Drachsler, Paul A. Kirschner) (2025)
- Maschinen mit Heisshunger (Enrico Kampmann) (2025)
- Looking beyond the Hype - Understanding the Effects of AI on Learning (Elisabeth Bauer, Samuel Greiff, Arthur C. Graesser, Katharina Scheiter, Michael Sailer) (2025)
- The Impact of Generative AI on Critical Thinking - Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers (Hao-Ping (Hank) Lee, Advait Sarkar, Lev Tankelevitch, Ian Drosos, Sean Rintel, Richard Banks, Nicholas Wilson) (2025)
- Saying ‘Thank You’ to ChatGPT Is Costly - But Maybe It’s Worth the Price. (Sopan Deb) (2025)
- Reddit-User mit KI-Bots getäuscht - das fragwürdige Experiment der Universität Zürich (Adrienne Fichter, Patrick Seemann) (2025)
- Ein Buch lesen? Ganz?! (Anant Agarwala, Martin Spiewak) (2025)
- Zur Diskussion: KI in der Grundschule - Grundschule aktuell Heft 170 (2025)
- Künstliche Intelligenz in der Primarstufe - Chancen, Herausforderungen, Perspektiven (Thomas Irion, Taha Ertuğrul Kuzu) (2025)
- Künstliche Intelligenz in der Primarstufe - Chancen, Herausforderungen, Perspektiven (Thomas Irion, Taha Ertuğrul Kuzu) (2025)
- Forschung & Lehre 5/25 (2025)
- Verzichtbar oder notwendig? - KI-Folgenabschätzung für die Hochschule (Gabi Reinmann)
- Verzichtbar oder notwendig? - KI-Folgenabschätzung für die Hochschule (Gabi Reinmann)
- Teach AI literacy - A Guide for Teachers (Judy Robertson) (2025)
- The effect of ChatGPT on students’ learning performance, learning perception, and higher-order thinking - insights from a meta-analysis (Jin Wang, Wenxiang Fan) (2025)
- Replies to criticisms of my posts on ChatGPT & the environment (Andy Masley) (2025)
- JAMESfocus – Künstliche Intelligenz im Alltag von Jugendlichen (Gregor Waller, Svenja Deda-Bröchin, Jael Bernath, Céline Külling-Knecht, Isabel Willemse, Lilian Suter, Pascal Streule, Mirjam Jochim, Daniel Süss) (2025)
- What went (methodologically) wrong with the ChatGPT in education meta-studies (Ilkka Tuomi) (2025)
- These AI Tutors For Kids Gave Fentanyl Recipes And Dangerous Diet Advice (Emily Baker-White) (2025)
- Adjusting for Publication Bias Reveals No Evidence for the Effect of ChatGPT on Students’ Learning Performance, Learning Perception, and Higher-Order Thinking (František Bartoš, Patrícia Martinková, Eric-Jan Wagenmakers) (2025)
- Faul und inkompetent? KI-Nutzung schadet dem Image im Büro (Sven Festag) (2025)
- The AI Con - How to Fight Big Tech's Hype and Create the Future We Want (Emily M. Bender, Alex Hanna) (2025)
- The Professors Are Using ChatGPT, and Some Students Aren’t Happy About It (Kashmir Hill) (2025)
- Plapperbots mit Selbstreflektion - Acht KI-Sprachmodelle mit Reasoning-Funktionen im Test (Jo Bager, Hartmut Gieselmann) (2025)
- Denkbar echt simuliert - KI versus Gehirn: so ähnlich, so unterschiedlich, so undurchschaubar (Andrea Trinkwalder) (2025)
- The Collapse of GPT (Neil Savage) (2025)
- Empire of AI - Dreams and Nightmares in Sam Altman's OpenAI (Karen Hao) (2025)
- KI als Motor für eine zukunftsfähige Schweizer Bildungslandschaft (Charles-Edouard Bardyn) (2025)
- AI and the Entry-Level Problem (Tom Davenport) (2025)
- Empowering Learners for the Age of AI - An AI Literacy Framework for Primary and Secondary Education (Review draft) (OECD Organisation for Economic Co-operation and Development) (2025)
- Praktische Hinweise für die Nutzung von KI im Unterricht (Thomas Zurfluh) (2025)
- Wie man ChatGPT an einer Hochschule nicht verwenden sollte (Martin Steiger) (2025)
- Im Rausch der Algorithmen (Markus Thomas Münter) (2025)
- «Sora hat mir mehr geholfen als die menschlichen Therapeuten» (Valeria Mazzeo, Anielle Peterhans) (2025)
- Schule heute 6/25 (2025)
- Was ist denn überhaupt KI? - Ein einleitendes Glossar (Xenia Klaffke) (2025)
- Bildungsrevolution dank KI?!
- Was ist denn überhaupt KI? - Ein einleitendes Glossar (Xenia Klaffke) (2025)
- Understanding the Impacts of Generative AI Use on Children (Youmna Hashem, Saba Esnaashari, Kate Onslow, Sukankana Chakraborty, Anton Poletaev, John Francis, Jonathan Bright) (2025)
- Exploring the Inclusive Potential of AI Chatbots - Engagement and Barriers in Foreign Language Training (Christa Schmid-Meier, Lea Schulz) (2025)
- The Illusion of Thinking - Understanding the Strengths and Limitations of Reasoning Models
via the Lens of Problem Complexity (Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, Mehrdad Farajtabar) (2025)
- Your Brain on ChatGPT - Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task (Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, Pattie Maes) (2025)
- Literarisches Schreiben in der Schule– mit (und ohne?) KI (Philippe Wampfler) (2025)
- Apple-Paper: Warum Reasoning-Modelle wohl nicht denken - Sie brauchen viel Leistung, liefern aber nicht immer bessere Ergebnisse: Large Reasoning Models sollen die KI revolutionieren. Eine Apple-Studie kritisiert das. (Ben Schwan) (2025)
- Computer, mach meinen Job! (Ronald Eikenberg) (2025)
- «Schreibe wie ein 15-Jähriger!» (Ulf Schönert) (2025)
- The Cognitive Debt of Digging Through Preprints - Your Brain on MIT Media Lab (Ben Shindel) (2025)
- Erziehungswissenschaft nach ChatGPT - Mitteilungen der Deutschen Gesellschaf für Erziehungswissenschaft - Heft 70. Jg 36/2025 (2025)
- Künstliche Intelligenz frisst immer mehr Strom (2025)
- Generative AI without guardrails can harm learning - Evidence from high school mathematics (Hamsa Bastani, Osbert Bastani, Alp Sungu, Haosen Ge, Özge Kabakcı, Rei Mariman) (2025)
- Datennutzungspolitik im Bildungsraum Schweiz - Entwicklungsansätze für eine kohärente Umsetzung (educa.ch Schweizerisches Medieninstitut für Bildung und Kultur, Nelly Buchser-Heer, Martina Eyer, Karen Grossmann, Tobias Schlegel) (2025)
- «Wir müssen fast betteln, dass wir mitreden können» (Daniel Graf) (2025)
- Hilfe! Ich fühle mich wie Goethes Zauberlehrling (Doris Weßels) (2025)
- How Do You Teach Computer Science in the A.I. Era? (Steve Lohr) (2025)
- Künstliche Intelligenz in DaF/DaZ (Luisa Baum, Gülsüm Günay) (2025)
- Die Psychologie und die Künstliche Intelligenz - Maschinen, Bewusstsein und die menschliche Psyche (Oliver Hoffmann) (2025)
- Einleitung: Denksysteme im Wandel - Mensch und Maschine
- Maschinenbewusstsein: Mythos oder Wirklichkeit?
- Einleitung: Denksysteme im Wandel - Mensch und Maschine
- «Gewisse Lehrer könnte man mit KI komplett ersetzen» (Anna Luna Frauchiger) (2025)
- KI-Boom an Schulen - PHs bauen Angebote für angehende Lehrer aus (Daniel Graf) (2025)
- Hirn aus, KI an (Gioia da Silva, Leonid Leiva Ariosa) (2025)
- KI-Einsatz steckt noch in den Kinderschuhen (Anna Luna Frauchiger, Nina Fargahi) (2025)
- Künstliche Intelligenz (KI) im Schulunterricht (2025)
- Was kann das Chat-GPT der ETH? «Mehr als 1000 Sprachen» (Joachim Laukenmann) (2025)
- Me, myself and AI - Understanding and safeguarding children’s use of AI chatbots (Internet Matters) (2025)
- Death by AI - One man's struggle with his mortality (Dave Barry) (2025)
- World Wide Worries - AI is killing the web. Can anything save it? (Anonymus) (2025)
- Warum die KI uns das Sehen lehrt (Dario Veréb) (2025)
- «Diese Blase wird platzen» (Karen Hao, Ruth Fulterer) (2025)
- Wenn die sprechende KI-Barbie die beste Freundin des Kindes wird (Edouard Gentaz, Catherine Cochard) (2025)
- Generative KI in Studium und Lehre - Die Bedeutung fachlichen Wissens für kritisches Denken (Gabi Reinmann) (2025)
- Generative AI IS the Marshmallow Test - Unfortunately We Live in a Society of Sanctioned Marshmallow Pushers (Timothy Burke) (2025)
- KI-Chatbots im Programmierunterricht mit Scratch - Eine explorative Studie zum Einsatz von KI-Chatbots im Programmierunterricht mit Scratch in der Sekundarstufe I (Melanie Kieber) (2025)
- Wenn wir nicht mehr lernen müssen (Sibylle Anderl) (2025)
- Der KI-Plan der USA: Chauvinistisch, kolonialistisch und maximale Zensur (Adrienne Fichter) (2025)
- study smart – with AI - Dein Guide für kluge Entscheidungen mit KI (Mareike Bartels, Fridrun Freise) (2025)
- Neue Mündlichkeit - Kommunikation und KI im Unterricht (Stefan Hofer-Krucker Valderrama, Rémy Kauffmann) (2025)
- ICER 2025 - Proceedings of the 2025 ACM Conference on International Computing Education Research (Leo Porter, Neil Brown) (2025)
- Model Context Protokoll - Special von c't (2025)
- KI arbeitet für Sie - Mit dem Model Context Protocol greifen KI-Modelle auf Apps und Daten zu (Jo Bager, Ronald Eikenberg) (2025)
- Hilfskraft mit Potenzial - MCP im Einsatz auf dem Desktop (Jo Bager, Ronald Eikenberg)
- KI arbeitet für Sie - Mit dem Model Context Protocol greifen KI-Modelle auf Apps und Daten zu (Jo Bager, Ronald Eikenberg) (2025)
- Tschüss, Lehrer! (René Donzé) (2025)
- DeutschGPT – Deutschunterricht im Dialog mit Künstlicher Intelligenz (Hans-Georg Müller, Maurice Fürstenberg) (2025)
- KI im Klassenzimmer: Positive Lernrevolution oder Förderung der Denkfaulheit? (Joachim Laukenmann) (2025)
- Wissenschaftler warnen vor Folgen der Motion Gössi (Anonymus) (2025)
- Canaries in the Coal Mine? - Six Facts about the Recent Employment Effects of Artificial Intelligence (Erik Brynjolfsson, Bharat Chandar, Ruyu Chen) (2025)
- Reaktion auf KI: Universität Zürich prüft Doktorarbeiten künftig auch mündlich (Helene Obrist) (2025)
- «Diebstahl» oder «Training»? - Der Streit um KI-Daten erreicht die Schweiz (Edith Hollenstein) (2025)
- St. Galler KI-Kompetenzrahmen für die Bildung (Steve Bass, Josef Buchner, Manuel Garzi, Lisa Hermann, Martin Hofmann, Maria Mannai, Samuel Müller, Charlotte Nüesch, Konstantin Papageorgiou, Stefanie Schallert-Vallaster, Georg Winder) (2025)
- The Stanford AI Jobs Paper: It's Not What You Think (Marcel Salathé) (2025)
- Artificial Writing and Automated Detection (Brian Jabarian, Alex Imas) (2025)
- AI and the future of education - Disruptions, dilemmas and directions (UNESCO United Nations Educational, Scientific and Cultural Org.) (2025)
- KI-Transformation in Deutschland - Veränderungen in Gesellschaft, Kultur, Bildung und Wirtschaft (Thomas Breyer-Mayländer, Dirk Drechsler, Christopher Zerres) (2025)
- Ethischer & rechtlicher Leitfaden für den verantwortungsvollen Einsatz von KI in der Bildung ( Maria Bertel, Evelyne Putz, Julian Priebsch, Dovilė Balcevičienė, Danguolė Mačiulienė, Ričardas Balcevičius, Cristina Obae) (2025)
- «Der Hype war schon immer der Modus Operandi der KI-Forschung» (Alex Hanna, Emily M. Bender, Daniel Hackbarth) (2025)
- AI and education - Protecting the rights of learners (UNESCO United Nations Educational, Scientific and Cultural Org.) (2025)
- Schooling the (Artificially) Intelligent Writer - GenAI Technologies as Thinking Infrastructures in School Education (Toon Tierens, Mathias Decuypere, Sigrid Hartong, Samira Alirezabeigi) (2025)
- Trendmonitor KI in der Bildung (Deutsche Telekom Stiftung) (2025)
- Statt von einer Lehrperson lassen sich Schüler von der KI Nachhilfe geben (Fabienne Riklin) (2025)
- Guten Morgen, Frau KI! (Uwe Jean Heuser) (2025)
- Schule 2035 - Lernen nach Digitalisierung & KI (Jöran Muuß-Merholz) (2025)
- Schule 1: Die Lisa-Rosa-Reformschule - die global vernetzten Weltverbesserer*innen
- Schule 3: Die LIDA-Schulen - KI-automatisierte Lerneffizienz in schönen Räumen
- Schule 1: Die Lisa-Rosa-Reformschule - die global vernetzten Weltverbesserer*innen
- Grenzen überwinden - voneinander lernen (Mareen Grillenberger, Andreas Grillenberger) (2025)
- AI-Generated “Workslop” Is Destroying Productivity (Kate Niederhoffer, Gabriella Rosen Kellerman, Angela Lee, Alex Liebscher, Kristina Rapuano, Jeffrey T. Hancock) (2025)
- Der Einsatz von KI befreit nicht vom Selberdenken (Klaus Zierer) (2025)
- Kluge Köpfchen mit KI - Der Kompass für Schule,Leben & Lernen (Kai Spriestersbach, Leonie Lutz) (2025)
- Can Large Language Models Develop Gambling Addiction? (Seungpil Lee, Donghyeon Shin, Yunjeong Lee, Sundong Kim) (2025)
- Kreativ sein ohne KI? - Brief an einen fiktiven Studenten (Gabi Reinmann) (2025)
- Balancing Minds and Data - The Privacy Dilemma of LLMs and Anthropomorphism in LLMs (Raffael Meier) (2025)
- KI in der Hochschulbildung (Beatrix Busse, Ingo Kleiber) (2025)
- 1. Einleitung
- 2. Warum KI und Bildung
- 3. Hallo KI - KI immer wieder kennenlernen
- 4. Viel Lärm um KI - Diskurse über KI in der Bildung
- Weiß die KI, dass sie nichts weiß? - Wofür wir Chatbots und KI-Agenten nutzen sollten, wo sie sich irren und wo wir aufpassen müssen - ChatGPT und Co. einfach erklärt (Katharina A. Zweig) (2025)
- KI und der Schweizer Arbeitsmarkt - Erste Evidenz zu Auswirkungen auf Arbeitslosigkeit und Stellenausschreibungen (Jeremias Kläui, Michael Siegenthaler) (2025)
- strategie digital 6/25 - Generative KI als Gamechanger? (Hochschulforum Digitalisierung) (2025)
- Killt die KI meinen Job? - Gewinner und Verlierer der neuen Arbeitswelt (Schwerpunktthema Spiegel 41/2025) (2025)
- «Was die Juniorprojektmanagerin gemacht hat, übernimmt heute die KI» (Larena Klöckner) (2025)
- Der Chatbot, mein Angstgegner (Benjamin Bidder) (2025)
- «Was die Juniorprojektmanagerin gemacht hat, übernimmt heute die KI» (Larena Klöckner) (2025)
- KI: Der Tod des Internets (Mario Sixtus) (2025)
- «Die Verführung dieser Maschinen ist riesengroß» (Katharina Zweig, Simon Berlin) (2025)
- Vibe engineering (Simon Willison) (2025)
- Heads we win, tails you lose - AI detectors in education (Mark A. Bassett, Wayne Bradshaw, Alyce Hogg, Kane Murdoch, Hannah Bornsztejn, Bridget Pearce, Colin Webber) (2025)
- Künstliche Intelligenz und Wir - Stand, Nutzung und Herausforderungen der KI (Frank Schmiedchen, Alexander von Gernler, Martina Hafner, Klaus Peter Kratzer) (2025)
- Große Sprachmodelle (Carsten Arzig)
- IT-Infrastrukturen und deren Stromverbrauch (Dieter Kranzlmüller, Andrew Grimshaw)
- Große Sprachmodelle (Carsten Arzig)
- The A.I. Prompt That Could End the World (Stephen Witt) (2025)
- Enshittification - Why Everything Suddenly Got Worse and What To Do About It (Cory Doctorow) (2025)
- Teaching the AI-Native Generation - Empowering Schools in the Age of AI (Oxford University Press) (2025)
- Wissenschaftliche Abschlussarbeiten im KI-Zeitalter - Disruption, Herausforderungen und neue Bewertungsansätze (Doris Weßels, Annabell Bils, Jannica Budde) (2025)
- Künstliche Intelligenz in Seminar- und Abschlussarbeiten - Ein Praxisleitfaden für Studierende mit Handlungsempfehlungen, Prompt-Beispielen und kritischer Einordnung (Fabian Lang) (2025)
- Technischer Hintergrund: Große Sprachmodelle (LLM)
- Prompt Engineering: Gute Frage, gutes Ergebnis
- Dokumentation: Wissenschaftliche Integrität bewahren
- Planung: KI bei der Konzeption
- Literatur: KI bei der Recherche
- Schreiben: KI bei der Texterstellung
- Feinschliff: KI bei der Schlussredaktion
- Technischer Hintergrund: Große Sprachmodelle (LLM)
- L'IA en éducation - cadre d'usage (Ministre de l'Éducation nationale) (2025)
- Lehren & Lernen in Zeiten künstlicher Intelligenz (2025)
- Künstliche Intelligenz ist kein Werkzeug - Warum Bildung über «Anwendungskompetenzen» hinausgehen muss (Tilman Michaeli)
- Künstliche Intelligenz ist kein Werkzeug - Warum Bildung über «Anwendungskompetenzen» hinausgehen muss (Tilman Michaeli)
- Empfehlungen für KI-Leitlinien des PH-Verbunds Süd-Ost - Verantwortungsvolle Nutzung von Künstlicher Intelligenz in Studium, Lehre, Forschung und Verwaltung (Thomas Leitgeb, Katharina Maitz, Herbert Gabriel, Corinna Mößlacher, Marlies Matischek-Jauk) (2025)
- Rentier mit fünf Beinen wird in der Migros zum Verkaufsschlager (Manuel Stocker) (2025)
- «KI-Revolution» - Bedrohung oder Chance für Arbeitsplätze? (Joachim Laukenmann) (2025)
- «Das ging überraschend schnell» (Malin Hunziker, Florian Seliger) (2025)
- «Mit KI füttern wir eine kleine Kaste, die wenig Interesse an Demokratie hat» (Philipp Theisohn, Alexandra Kedves) (2025)
- Let Them Eat Large Language Models - Artificial Intelligence and Austerity in the Neoliberal University (Martha Kenney, Martha Lincoln) (2025)
- From Offloading to Engagement - An Experimental Study on Structured Prompting and Critical Reasoning with Generative AI (Michael Gerlich) (2025)
- AI and the Future of Learning (Ben Gomes, Lila Ibrahim, Yossi Matias, Christopher Phillips, James Manyika) (2025)
- Maschinensturm KI (Aurelie Herbelot, Eva von Redecker) (2025)
- Pädagogik 11/25 (2025)
- Das dreifache Warum (Jöran Muuß-Merholz) (2025)
- Das dreifache Warum (Jöran Muuß-Merholz) (2025)
- «Meine einstigen Stammkunden brauchen mich nicht mehr» (Verena Töpper) (2025)
- Fake-News-Websites machten mich zur Partnerin eines Promi-Rappers. Und ich kann nichts dagegen tun (Celina Euchner, Oliver Zihlmann) (2025)
- JIM-Studie 2025 (Thomas Rathgeb, Thomas Schmid, Sabine Feierabend, Yvonne Gerigk, Stephan Glöckler) (2025)
- Hinterbliebene zahlen 200’000 Dollar, damit Peter nach dem Tod zu ihnen «sprechen» kann (Catherine Cochard) (2025)
- Energieengpässe wegen KI - Boom von KI-Rechenzentren treibt die US-Strompreise (Greta Friedrich) (2025)
- Kompass Künstliche Intelligenz - Ein Reiseführer durch eine Welt in verrückten Zeiten (Marcel Salathé) (2025)
- EU Kids Online Schweiz 2025 - Chancen und Risiken für Kinder und Jugendliche im Internet (Martin Hermida, Marco Hartmann) (2025)
- Künstliche Intelligenz als Lernhelfer (Hedwig Lichtenstern) (2025)
- Klaus Zierer: Warum Schulen jetzt vier Verbote brauchen (Klaus Zierer) (2025)
- ChatGPT gibt dir dafür eine Drei (Ulf Schönert) (2025)
- DigComp 3.0 - European Digital Competence Framework - Fifth Edition (J. Cosgrove, R. Cachia) (2025)
- So nah und doch so fern - KI in der Schule (Hendrik Haverkamp, Robin Ahrens) (2025)
- AI Fatigue: Reflections on the Human Side of AI’s Rapid Advancement (Victor Dibia) (2025)
- Guidance on AI and Children - Updated guidance for governments and businesses to create AI policies and systems that uphold children’s rights (UNESCO United Nations Educational, Scientific and Cultural Org.) (2025)
- At home and at school, AI is transforming childhood - It brings many benefits, but also hidden dangers (Anonymus) (2025)
- Kompass: Künstliche Intelligenz und Kompetenz 2025 - Einstellungen, Handeln und Kompetenzentwicklung im Kontext von KI (Laura Cousseran, Achim Lauber, Niels Brüggen, Laura Sūna, Cornelia Bogen) (2025)
- KI nimmt den Werbern die Aufträge weg (Janique Weder) (2025)
- Wir, das Volk, sind die Superintelligenz (Audrey Tang) (2025)
- Cyborgs, Centaurs and Self-Automators - The Three Modes of
Human-GenAI Knowledge Work and
Their Implications for Skilling and the Future of Expertise (Steven Randazzo, Hila Lifshitz, Katherine C. Kellogg, Fabrizio Dell'Acqua, Ethan Mollick, François Candelon, Karim R. Lakhani) (2025)
- Ein Riese erwacht (Leonid Leiva Ariosa) (2025)
- Designing Education Ecosystems for the Future: The Role of Digital Technologies - EdusummIT 2025 (2025)
- 5. Artificial Intelligence (AI) literacy for teaching and learning: design and implementation - Thematic Working Group 5 (Mary Webb, Matt Bower, Ana Amélia Carvalho, Fredrik Mørk Røkenes, Jodie Torrington, Jonathan D. Cohen, Yousra Chtouki, Kathryn MacCallum, Tanya Linden, Deirdre Butler, Juliana E. Raffagheli, Henriikka Vartiainen, Martina Ronci, Peter Tiernan, David M. Smith, Chris Shelton, Joyce Malyn-Smith, Pierre Gorissen)
- 5. Artificial Intelligence (AI) literacy for teaching and learning: design and implementation - Thematic Working Group 5 (Mary Webb, Matt Bower, Ana Amélia Carvalho, Fredrik Mørk Røkenes, Jodie Torrington, Jonathan D. Cohen, Yousra Chtouki, Kathryn MacCallum, Tanya Linden, Deirdre Butler, Juliana E. Raffagheli, Henriikka Vartiainen, Martina Ronci, Peter Tiernan, David M. Smith, Chris Shelton, Joyce Malyn-Smith, Pierre Gorissen)
- KI-Detektoren funktionieren - und warum viele Menschen das Gegenteil behaupten (Philippe Wampfler) (2025)
- Können KI-Detektoren KI-generierte Texte von menschengemachten Texten unterscheiden? (Dominic Hassler) (2025)
- GenAI in Higher Education - Redefning Teaching and Learning (Sam Illingworth, Rachel Forsyth) (2025)
- Less stress, better scores, same learning - The dissociation of performance and learning in AI-supported programming education (Patrick Bassner, Ben Lenk-Ostendorf, Ramona Beinstingel, Tobias Wasner, Stephan Krusche) (2025)
- «Ich rate davon ab, Superintelligenzen überhaupt erst anzustreben» (Katharina Zweig, Joachim Laukenmann, Jan Bolliger) (2025)
- Wie kann ich mit Chat-GPT noch eigenständig denken? (Nils Althaus) (2025)
- Schon Zehnjährige schreiben mit KI (Sabrina Bundi) (2025)
- So geht Schule - Bildung und Erfolg im Zeitalter von KI und ChatGPT (Marcus Diekmann, Daniel Jung) (2025)
- Im Dialog mit der Maschine (Barnaby Skinner) (2025)
- KI als Malware-Mastermind - Medienhype oder reale Bedrohung? (Olivia von Westernhagen) (2026)
- Schule gegen Kinder - Wie ein kaputtes Bildungssystem die Zukunft der nächsten Generation gefährdet (Silke Müller) (2026)
- Wissensmanagement mit Künstlicher Intelligenz - Erfahrungswissen effizient sichern und transferieren (Nicole Ottersböck, Holger Dander, Sascha Stowasser) (2026)
- Wissenstransfer im Maschinenservice - Die Bedeutung von Wissen, Ansätze künstlicher Intelligenz und praktische Tipps (Julie Chaput, Patrick Deutschmann, Sina Volkmann)
- Wissenstransfer im Maschinenservice - Die Bedeutung von Wissen, Ansätze künstlicher Intelligenz und praktische Tipps (Julie Chaput, Patrick Deutschmann, Sina Volkmann)
- Mediensozialisation in «smarten» Umgebungen - Selbst- und Sozialwerdung im Kontext von Datafizierung und Automatisierung (Laura Sūna, Wolfgang Reißmann) (2026)
- Die Maschine «KI» - Gesamtgesellschaftliche Herausforderung und (medien-)pädagogische Aufgabe (Thomas Hickfang, Bernd Schorb, Helga Theunert)
- Die Bibliothek von Babel - Vom Wissen zum Gewussten und die Grenzen des Computers (Friedrich Krotz)
- Die Maschine «KI» - Gesamtgesellschaftliche Herausforderung und (medien-)pädagogische Aufgabe (Thomas Hickfang, Bernd Schorb, Helga Theunert)
- Forschung & Lehre 1/26 (2026)
- Denken lernt man nur beim Denken (Klaus Zierer) (2026)
- Informatives Feedback - Wie Künstliche Intelligenz beim Studium unterstützen kann (Friedrich Hesse, Friederike Invernizzi)
- Der Wert des Schreibens - Ergebnisse einer Studierendenbefragung zur KI-Nutzung (Nora Hoffmann, Sarah Schmidt) (2026)
- Denken lernt man nur beim Denken (Klaus Zierer) (2026)
- KI kinderleicht?! Teil 1 (2026)
- Datenleck im Bundeshaus (Reto Vogt) (2026)
- Atomkraft für Chatbots - Warum in den USA wieder massiv in Kernenergie investiert wird (Eva Thiébaud) (2026)
- Gespräch zu «Designing Organizations for an Information-Rich World» (Google Notebook LLM) (2026)
- Die Sehnsucht nach dem einen Framework - Warum uns immer neue Orientierungsrahmen nicht retten – und was sie über unseren Umgang mit Transformation verraten (Stephanie Wössner) (2026)
- The emerging submission crisis in behavioral science (Markus Wolfgang Hermann Spitzer) (2026)
- Attention is all you need (Beat Döbeli Honegger) (2026)
- OECD Digital Education Outlook 2026 (OECD Organisation for Economic Co-operation and Development) (2026)
- Betrüger knöpfen Schwyzer Firma mehrere Millionen ab (2026)
- Fobizz als «Schlüssel zur KI-Welt»? - Wie ein Unternehmen die Integration von KI im deutschen Schulwesen prägt (Lucas Joecks) (2026)
- KI-Startup Sparkli sammelt 5 Millionen ein (Mark Schröder) (2026)
- KI-Bezogene Schulleitungsfortbildungen in Deutschland (Forum Bildung Digitalisierung, Hannah Glinka, Sarah Fichtner, Judith Wenninger, Franziska Matzen) (2026)
- Sieben Mythen der KI-Nutzung (Sandra Schön, Benedikt Brünner, Martin Ebner, Sarah Diesenreither, Barbara Hanfstingl, Georg Krammer) (2026)
- Bis zu 340 Dollar Stundenlohn (Marie-Astrid Langer) (2026)
- Vom Deskilling zum Newskilling - Der blinde Fleck emergenter Kompetenzverschiebungen durch generative KI (Doris Weßels, Miriam Maibaum) (2026)
- Denken auslagern macht dumm (Arne Grävemeyer) (2026)
- Gefahr: kognitive Auslagerung - KI-Forscher Michael Gerlich: Der bequeme Mitarbeiter ersetzt sich selbst (Michael Gerlich, Arne Grävemeyer) (2026)
- Building a C compiler with a team of parallel Claudes (Nicholas Carlini) (2026)
- European children’s use and understanding of Generative AI (Elisabeth Staksrud, Giovanna Mascheroni, Tijana Milosevic, Niamh Ní Bhroin, Kjartan Ólafsson, Gülbin Şengül-İnal, Mariya Stoilova) (2026)
- AI Doesn’t Reduce Work—It Intensifies It (Aruna Ranganathan, Xingqi Maggie Ye) (2026)
- Something Big Is Happening (Matt Shumer) (2026)
- KI in Lehre, Weiterbildung und Training (Dominik Freinhofer) (2026)
- Der wahre Engpass: Warum schnelleres Coden Projekte nicht beschleunigt (Golo Roden) (2026)
- Gut im Raten, schlecht im Verstehen (Michel Hauswirth) (2026)
- Mehr Schaden als Hilfe (Gioia da Silva) (2026)
- Medienkompetenz im KI-Zeitalter - für Studium und Wissenschaf (Rödiger Voss) (2026)
- Bildung überdenken (Alois Hundertpfund, Werner Hartmann) (2026)
- KI wird zu einer Gefahr für unsere Demokratie (Mirko Bischofberger, Robert West) (2026)
- Agents of Chaos (Natalie Shapira, Chris Wendler, Avery Yen, Gabriele Sarti, Koyena Pal, Olivia Floody, Adam Belfki, Alex Loftus, Aditya Ratan Jannali, Nikhil Prakash, Jasmine Cui, Giordano Rogers, Jannik Brinkmann, Can Rager, Amir Zur, Michael Ripa, Aruna Sankaranarayanan, David Atkinson, Rohit Gandikota, Jaden Fiotto-Kaufman, EunJeong Hwang, Hadas Orgad, P Sam Sahil, Negev Taglicht, Tomer Shabtay, Atai Ambus, Nitay Alon, Shiri Oron, Ayelet Gordon-Tapiero, Yotam Kaplan, Vered Shwartz, Tamar Rott Shaham, Christoph Riedl, Reuth Mirsky, Maarten Sap, David Manheim, Tomer Ullman, David Bau) (2026)
- Ich habe eine App gebaut. Ich kann nicht programmieren. - Was passiert, wenn Lehrpersonen ihre eigenen digitalen Werkzeuge bauen? (2026)
- How Teens Use and View AI (Colleen McClain, Monica Anderson, Olivia Sidoti, William Bishop) (2026)
- KI als Managementaufgabe der Hochschule - Den Umgang mit KI in sinnvolle Bahnen lenken - eine Heuristik zur Sinnbildung und organisationalen Verankerung in Studium und Lehre (Jens Tobler) (2026)
- Wie viel produktiver werden wir dank der künstlichen Intelligenz wirklich? (Simon Schmid) (2026)
- I Ran Local AI on My MacBook and iPhone - The Gap Is Closing Fast (Pawel Jozefiak) (2026)
- Künstliche Intelligenz als Einfallstor für Hacker: Die neue Verwundbarkeit (Max Muth) (2026)
- Schulblatt 1/2026 - KI im Klassenzimmer (2026)
- Spielerischer Praxistest (Jacqueline Olivier)
- «Wir müssen Lernen mit und Lernen ohne KI ermöglichen» (Dominik Petko, Jacqueline Olivier)
- Gemeinsam einen schuleigenen Rahmen gestalten (Sabina Galbiati)
- Spielerischer Praxistest (Jacqueline Olivier)
- Artificial intelligence, cognitive offloading and implications for education (Jason M. Lodge, Leslie Loble) (2026)
- Die unerwartete Avantgarde der KI (Barnaby Skinner) (2026)
- Coding After Coders - The End of Computer Programming as We Know It (Clive Thompson) (2026)
- Regelwerke zu KI an Schulen - Überblick und Analyse (Deutsche Telekom Stiftung) (2026)
- The Promptware Kill Chain (Bruce Schneier, Oleg Brodt, Elad Feldman, Ben Nassi) (2026)
- Nett, aber untauglich (Reto Vogt) (2026)
- Lernen und schummeln mit künstlicher Intelligenz (Giorgio Scherrer) (2026)
- Pro Juventute Jugendstudie 2026 - Umgang mit Stress, Krisen, Mediennutzung und Resilienz bei Jugendlichen und jungen Erwachsenen in der Schweiz (Lulzana Musliu, Susanne Walitza, Nathalie Bredenkamp, Serafin Schoch, Fabian Bergmann, Anna Werling, Lukasz Smigielski) (2026)
- Das ist erst der Anfang des Chaos (Eva Wolfangel) (2026)
- Welches Studium hat in Zeiten von KI noch Zukunft? (Jacob Gehring) (2026)
- Texte ohne und mit KI schreiben - das Uetiker Konzept für den Maturaufsatz (Philippe Wampfler) (2026)
- Einsatz von KI in den Schulen des Kantons Schwyz - Interpellation I 9/26 (Ueli Kistler, Angela Ruoss, Jan Stocker, Thomas von Euw) (2026)
- The Evidence Base on AI in K-12: A 2026 Review - The existing research on the impacts of AI on students and teachers (Lily Fesler, JP Martinez Claeys, Chris Agnew, Susanna Loeb) (2026)
- 95 Prozent von der KI (Renato Beck) (2026)
- Digitale Lernplattformen in der Volksschule - Überlegungen zu Potenzialen, Herausforderungen und Einflüssen auf das Lehren und Lernen (Beat Döbeli Honegger, Michael Hielscher, Lennart Schalk, Michael Seemann) (2026)
- Schreiben auf Kurs - Mustertexte und Strategien für Bachelor- und Masterarbeiten (2026)
- telli oder Der Eingriff des Staates in den deutschen Bildungsmarkt - Eine Stellungname (EdTech-Verband e.V.) (2026)
- Hallucinated citations are polluting the scientific literature - What can be done? (Miryam Naddaf, Elizabeth Quill) (2026)
- Teaching academic writing in the age of AI (Zara Abrams) (2026)
- Herausforderungen bei der Integration generativer Künstlicher Intelligenz in die Berufsbildung - Studie im Rahmen des Forschungsprojekts DigiTraS II (Tessa Consoli, Dominik Petko, Philipp Gonon, Alberto Cattaneo) (2026)
- LLM Wiki (Andrej Karpathy) (2026)
- Schädlinge im Prompt - Promptware: Angriffe jenseits der Prompt-Injection (Sylvester Tremmel) (2026)
- Informatikunterricht planen und durchführen (Werner Hartmann, Stefanie Jäckel, Myke Näf, Raimond Reichert) (2026)
- Was und wie sollen Kinder mit KI lernen? (Martina Rau) (2026)
- Why Sal Khan’s AI revolution hasn’t happened yet, according to Sal Khan (Matt Barnum) (2026)
- Enhancing School Students’ Self-Regulated Learning through Generative AI Support (Tim Fütterer, Lisa Bardach, Jochen Kuhn, Stefan Daniel Keller, Peter Gerjets) (2026)
- KI in der Bildung: von Abhängigkeit zu Handlungsfähigkeit! - Künstliche Intelligenz und selbstreguliertes Lernen von Schüler:innen (Tim Fütterer, Rebekka Steinhäuser, Nina Udvardi-Lakos, Armin Fabian, Peter Gerjets, Florian Nuxoll, Christian Bock, Ulrich Trautwein) (2026)
- Macht die KI uns dumm? (Silke Fokken, Johann Grolle, Claus Hecking) (2026)
- Was wir für Lernen halten, ist oft keines mehr! (Roland Böttcher) (2026)
- Digitale Souveränität in der Lehrkräftebildung - Eine empirische Untersuchung professioneller Entwicklungsprozesse im Kontext generativer Künstlicher Intelligenz und des Physikunterrichts (Jannik Henze) (2026)
- AI Citation Drift: Wie stabil sind Quellen in AI-Suchergebnissen? (Johannes Beus) (2026)
- Wenn der Computer das Fahrrad für den Geist ist … (Beat Döbeli Honegger) (2026)
- «Alle geben sich so wahnsinnig zukunftsorientiert» (Gina -, Bea -, David Hunziker, Lukas Tobler) (2026)
- Den Chatbot entzaubern (Franziska Meister) (2026)
- KI kinderleicht?! Teil 2 - KI als Werkzeug im Unterricht (2026)
- Pädagogik 5/26 (2026)
- Die Grammatik des KI-Lernens (2026)
- Die Grammatik des KI-Lernens (2026)
- Alle werden programmieren – und genau das macht uns abhängig von Diktaturen und Demagogen - Ihr werdet alle programmieren (Moritz Zumbühl) (2026)
- Synergise. Strategise. Realise - SSC recommendations for AI computing infrastructure in the ERI domain (Schweizerischer Wissenschaftsrat) (2026)
- Onlinetest? Macht mein KI-Agent (Doris Weßels, Franca Quecke) (2026)
- Wurde Stromhunger von AKW-Lobby aufgebauscht? (Benjamin Bitoun, Edith Hollenstein) (2026)
- Der Knigge für den Umgang mit Chatbots (Reto Vogt) (2026)
- AI research papers are getting better, and it’s a big problem for scientists (Joshua Dzieza) (2026)
- Lausanner Firma lanciert auf Effizienz getrimmtes KI-Modell (Markus Städeli) (2026)
- Die KI bedroht unsere Urteilskraft (Ruth Fulterer) (2026)
- Book on Truth in the Age of A.I. Contains Quotes Made Up by A.I. (Benjamin Mullin) (2026)
- Bildung, Vertrauenswürdigkeit und Arbeitsmarkt im digitalen Wandel - Erkenntnisse und Überlegungen aus dem Nationalen Forschungsprogramm «Digitale Transformation» (NFP 77) (Leitungsgruppe des NFP 77) (2026)
- Artificial Intelligence Policy UC Berkeley School of Law (UC Berkeley School of Law) (2026)
- The Handbook of Critical Studies of Artificial Intelligence and Education (Wayne Holmes) (2026)
- Anthropic co-founder Chris Olah's remarks on Pope Leo XIV's encyclical «Magnifica humanitas» (Chris Olah) (2026)
- Law Professors Prefer AI Over Peer Answers (Alejandro Salinas, Carly Frieders, Neel Guha, Sibo Ma, Ralph Anzivino, Ian Ayres, Oren Bar-Gill, Omri Ben-Shahar, Stephen Friedman, George Geis, Sue Guan, Christoph Henkel, Stephanie Hoffer, Gregory Klass, Larasz Moody-Villarose, Sarath Sanga, Keith Sharfman, Justin Simard, Rebecca Stone, David Wishnick, Julian Nyarko) (2026)
- Aufregung um Chromes KI-Beigabe (Jo Bager) (2026)
- How One Oxford Student Used AI to Commit Academic Misconduct at Industrial Scale - And what it means for the quality of peer-reviewed conferences (Maria Sukhareva) (2026)
- Unlawful by Design - Expsoing the Hhuman Rights Costs of Generative AI (Amnesty International) (2026)
- Sherlock Holmes, ChatGPT, das Staatsexamen und ich (Anna Wolter) (2026)
- Eine KI, die Physik lernt wie ein Baby (Christian J. Meier) (2026)
- Wie Papst Leo gegen die Verzweckung des Menschen argumentiert (Felix Neumann) (2026)
- Kinder vertrauen ihre Sorgen KI-Diensten an (Edith Hollenstein) (2026)
- How People Are Really Using AI in 2026 (Marc Zao-Sanders) (2026)
- The cognitive impact of ChatGPT in higher education - A systematic review of critical and creative thinking outcomes (Changyue Li, Hang Cui, Linda Serra Hagedorn) (2026)
- Künstliche Intelligenz an unseren Schulen - Denkanstösse zu einem Zirkulationsmodell (Christoph Kraemer) (2026)
- AI in Higher Education - SSC considerations and recommendations (Schweizerischer Wissenschaftsrat) (2026)
- Atmospheric Analytics - Situated Encounters in the Age of Generative AI (Mathias Decuypere, Carlo Perrotta) (2026)
- An Inconvenient Truth About AI (Rutger Bregman) (2026)
- Wenn der beste Freund ein Chatbot ist - KI-Companions und Jugendschutz (Lucca Spohn) (2026)
- «Ich trete in das Vermächtnis eines Anspruchs» - Mario Voigt und KI (Aiko Kempen, Jonathan Peaceman) (2026)
- Why Do Chatbots Keep Telling Stories About Someone Named ‘Elias Thorne’? - Chatbots just aren't very creative. (AJ Dellinger) (2026)
- Kaufen KI-Unternehmen deutsche Antiquariate leer? (Wolfgang Tischer) (2026)
- Der Home-Run (Lorenz Honegger) (2026)
- Chatbot mit Kindersicherung (Ruth Fulterer) (2026)
- Ich habe mich selbst als KI nachgebaut. Sieht nicht gut aus für mich (Yves Bellinghausen) (2026)
- Praxisassistentin wird Expertin für KI - für 13'000 Franken (Edith Hollenstein) (2026)
- Lernende für das KI-Zeitalter befähigen - Ein KI-Kompetenzrahmen für die Primar- und Sekundarstufe (OECD Organisation for Economic Co-operation and Development) (2026)
- Algorithmus als Ankläger (Reto Vogt) (2026)
- Text ohne Autor (Anne Fromm) (2026)
- Die Grenzen der Detektoren (Raoul Spada) (2026)
- Misstrauen als Geschäftsmodell (Eva Wolfangel) (2026)
- Denken wie das verbreitete Mittelmaß (Malte Engeler) (2026)
- Bayern erlaubt generell KI-Einsatz bei Hochschul-Prüfungen (Petr Jerabek) (2026)
- «Zum Teil kennen nicht einmal die Partner sexuelle Fantasien. Aber Open AI schon» (Jessica Szczuka, Jannis Brühl) (2026)
- «Künstliche Intelligenz verschärft die Ungleichheit dramatisch» (Ulrike Malmendier, Simon Schmid) (2026)
- Diskreter Butler gesucht - Analyse: Wie Siri, Gemini und Copilot Ihr persönlicher Butler werden wollen (Hartmut Gieselmann) (2026)
- Eine verlorene Generation? (Nicole Althaus, Patrizia Messmer) (2026)
- Die AfD baut sich eine KI-Wutmaschine (Simon Widmer) (2026)
- Learning Under Algorithmic Conditions (Elizabeth de Freitas, Matthew X. Curinga, Ezekiel J. Dixon-Román, P. Taylor Webb) (2026)
- 1. Technics and Text - Guided by Gilbert Simondon (Elizabeth de Freitas)
- 1. Technics and Text - Guided by Gilbert Simondon (Elizabeth de Freitas)
 Anderswo finden
Anderswo finden
")

 Biblionetz-History
Biblionetz-History {kind=link}
{kind=link}